Multi-Agent AI EXPLAINED: How Magentic-One Works
Based on Sam Witteveen's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Magentic-One targets generalist multi-agent behavior while reducing common failure modes like loops and wrong tool usage.
Briefing
Multi-agent systems are shifting toward “generalist” agents that can handle many tasks without hand-coding every step—and Microsoft’s Magentic-One is built around a way to keep that flexibility from spiraling into loops, tool mistakes, or dead ends. The core idea is to avoid over-engineering a rigid node-by-node workflow while still adding enough structure for reliable progress tracking and recovery when things go wrong.
The landscape has largely split into two approaches. One relies heavily on letting a language model drive the agent’s actions, which can work until it doesn’t—then the system can drift, call the wrong tools, hand off to the wrong sub-agent, or get stuck repeating itself. The other approach tightly controls execution flow (for example, via graph-based orchestration), which improves reliability but often forces the agent into a narrower, more specialized behavior pattern and demands more engineering.
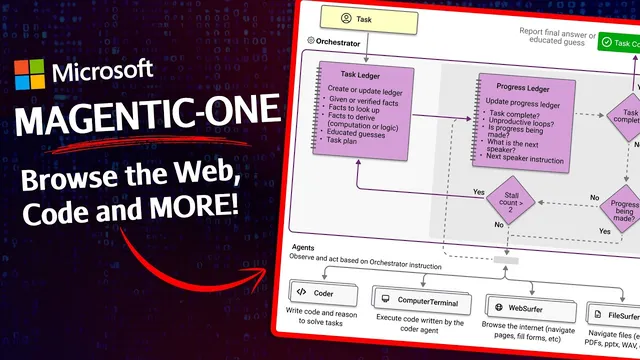
Magentic-One targets the middle ground: a generalist multi-agent architecture that can adapt across tasks without requiring fine-grained, step-by-step instructions for every scenario. It does this by introducing an orchestrator agent that acts as the decision-maker and coordinator. The orchestrator selects which specialized sub-agent should run next, passes it the right information, and—crucially—monitors progress over time.
That progress monitoring is where Magentic-One stands out. The orchestrator maintains two ledgers: a task ledger that stores the plan and what remains to be done, and a process ledger that reflects on completed versus incomplete steps as the work proceeds. If progress stalls or errors accumulate, the orchestrator can revise the plan—an outer loop that updates strategy—then re-enter an inner loop that executes step-by-step assignments to sub-agents. This repeated reflection-and-replanning cycle is designed to prevent the system from getting trapped in unproductive execution.
The sub-agents themselves cover common “capability slices.” A web surfer agent uses a Chromium-based browser with Playwright to navigate pages, extract information, and interact with content through actions like clicking and typing. A file server agent reads and navigates a local file system. A coding agent can write code, analyze information gathered by other agents, and produce new artifacts. A computer terminal agent executes shell commands, installs packages, and runs libraries—turning generated code into real outputs.
Magentic-One also leans into the idea of multi-model setups. GPT-4o can serve as the orchestrator, while smaller or specialized fine-tuned models can power sub-agents for narrower jobs (including potential RAG-style components). In the provided example—describing the latest trends in the S&P 500 using Y Finance—the orchestrator plans tool usage, assigns a coder to write a Python script (using yfinance and Pandas), uses an executor to run it, then compiles a brief report once the request is satisfied.
Beyond the architecture, Microsoft contributes benchmarking infrastructure via AutoGen Bench, built on the Autogen framework. Instead of measuring only language model quality, the benchmark aims to test the agentic system end-to-end, with repeatable, isolated runs that can compare different components and prompts. The project is positioned as an early iteration, with expectations that more specialist sub-agents and improvements will follow.
For builders, the practical takeaway is less about copying the whole system and more about adopting its structure: orchestrator-led planning, dual ledgers for progress accountability, and a reflection loop that can revise the plan when execution fails to move forward.
Cornell Notes
Magentic-One is Microsoft’s early attempt at a generalist multi-agent system that can tackle many tasks without requiring a rigid, step-by-step workflow. An orchestrator agent coordinates specialized sub-agents—web browsing, local file access, coding, and shell execution—while tracking execution using two ledgers: a task ledger for the plan and a process ledger for what’s completed versus what remains. If progress stalls or errors appear, the orchestrator updates the plan and re-enters execution, creating an outer (replan) loop and an inner (step execution) loop. The approach aims to reduce common failure modes of LLM-driven agents, like tool misuse and infinite loops, while keeping flexibility. Microsoft also introduces AutoGen Bench to benchmark agentic systems beyond raw model performance.
Why does Magentic-One avoid both “LLM drives everything” and “fully controlled graphs” approaches?
What are the two ledgers, and how do they change agent reliability?
How does the system recover when it hits errors or stalls?
What roles do the sub-agents play in a typical workflow?
How does the S&P 500 example illustrate the orchestrator’s planning and execution loop?
What does AutoGen Bench add for evaluating agent systems?
Review Questions
- How do the task ledger and process ledger work together to prevent an agent from continuing when progress stalls?
- In what ways does Magentic-One’s orchestrator differ from a purely LLM-driven agent or a strictly graph-controlled agent?
- Why is benchmarking an agentic system (not just an LLM) more complex, and how does AutoGen Bench attempt to address that?
Key Points
- 1
Magentic-One targets generalist multi-agent behavior while reducing common failure modes like loops and wrong tool usage.
- 2
An orchestrator agent selects which specialized sub-agent runs next and manages high-level planning and progress monitoring.
- 3
Dual ledgers—task ledger for the plan and process ledger for execution status—provide structured reflection during runtime.
- 4
When execution stalls or errors occur, the system can revise the plan via an outer loop and then continue via an inner step-execution loop.
- 5
Specialized sub-agents cover web browsing (Chromium + Playwright), local file access, coding/artifact creation, and shell execution.
- 6
The architecture supports multi-model setups, with GPT-4o as orchestrator and smaller or specialized models potentially powering sub-agents.
- 7
AutoGen Bench aims to benchmark agentic systems end-to-end, shifting evaluation from raw LLM performance to full agent behavior.