Multivariable Calculus 28 | Extreme Values With Constraints
Based on The Bright Side of Mathematics's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Unconstrained local extrema for C1 functions on open sets require ∇f=0, but this does not apply on constrained sets like curves.
Briefing
Local maxima and minima of multivariable functions usually come from where the gradient vanishes. That rule breaks down once the search is restricted to a constraint set—like a curve on a surface—because the function can still have nonzero gradient everywhere along the allowed points. The key fix is the method of Lagrange multipliers: at a constrained local extremum, the gradient of the objective function must align with the gradient of the constraint.
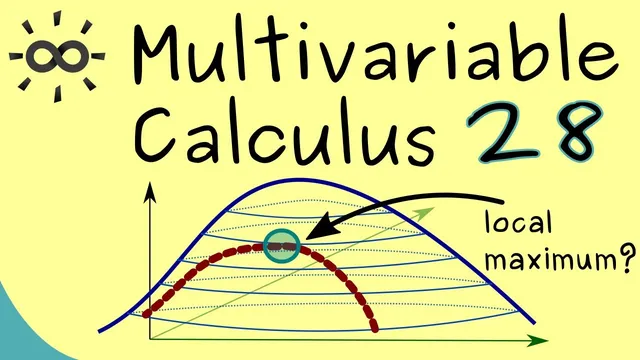
The discussion starts with a standard setup: for a C1 function f on an open subset of R2, local extrema can only occur at points where ∇f = 0. Geometrically, contour lines of f show where f is constant, and ∇f is perpendicular to those contours. If ∇f is not zero, moving in the gradient direction increases f, so an interior local extremum cannot happen.
Next comes the constrained version. Suppose the constraint is given by a C1 function G(x, y) = 0, which defines a curve in R2. Instead of optimizing f over all of R2, the goal is to optimize the restriction of f to the set G = {x ∈ R2 : G(x) = 0}. On this curve, the earlier “∇f = 0” condition becomes useless: the gradient of f can be nonzero at every point on the curve, even though the constrained maximum still exists. The geometric reason is that allowed moves are only along the constraint curve; the gradient direction may point off the curve, so it no longer guarantees an increase within the feasible set.
At a constrained local maximum, the contour of f must be tangent to the constraint curve. In gradient language, this means the direction perpendicular to the f-contours (∇f) must match the direction perpendicular to the constraint curve (∇G). Since ∇G is perpendicular to the contour line G = 0, the constrained extremum occurs precisely when ∇f and ∇G lie in the same one-dimensional subspace—equivalently, when ∇f is parallel to ∇G.
Formally, for a point x̃ on the constraint (so G(x̃) = 0), a necessary condition for f to have a local extremum subject to the constraint is that there exists a real number λ such that ∇f(x̃) = λ ∇G(x̃).
A second requirement is included to keep the constraint well-behaved: ∇G(x̃) must not be the zero vector, so the constraint curve has a meaningful tangent direction (it spans a one-dimensional subspace). The resulting implication is necessary but not sufficient: solving for points x̃ and multipliers λ that satisfy the equation identifies the only candidates for constrained extrema, but additional checks are still needed to confirm which candidates are actual maxima or minima.
The takeaway is practical and geometric at once: constrained extrema happen where the objective’s gradient lines up with the constraint’s gradient, with the scalar λ measuring how strongly the constraint “scales” that alignment.
Cornell Notes
For an unconstrained C1 function f on an open set in R2, local extrema can only occur where ∇f = 0. When optimization is restricted to a constraint curve defined by a C1 equation G(x, y) = 0, the condition ∇f = 0 no longer applies because feasible directions are limited to the curve. Along the constraint, ∇G is perpendicular to the contour line G = 0, while ∇f is perpendicular to the contour lines of f. A constrained local extremum occurs where these perpendicular directions match, meaning ∇f(x̃) is parallel to ∇G(x̃). This yields the Lagrange multiplier condition ∇f(x̃) = λ∇G(x̃) with G(x̃) = 0 and ∇G(x̃) ≠ 0. The condition is necessary, not sufficient.
Why does the usual unconstrained rule “∇f = 0” fail for constrained extrema on a curve G(x, y)=0?
What geometric relationship must hold between the contour lines of f and the constraint curve at a constrained local maximum?
What is the exact Lagrange multiplier condition in this R2 setup?
Why must ∇G(x̃) not be the zero vector?
Does solving ∇f(x̃)=λ∇G(x̃) guarantee a maximum or minimum?
Review Questions
- In the constrained setting, what replaces the condition ∇f=0, and why is it different?
- Explain how perpendicularity of gradients to contour lines leads to the equation ∇f(x̃)=λ∇G(x̃).
- What role does the requirement ∇G(x̃)≠0 play in the validity of the Lagrange multiplier condition?
Key Points
- 1
Unconstrained local extrema for C1 functions on open sets require ∇f=0, but this does not apply on constrained sets like curves.
- 2
A constraint curve can be written as G(x,y)=0, and the feasible domain is the set of points satisfying that equation.
- 3
Along the constraint, ∇f being nonzero does not automatically allow an increase because feasible moves are restricted to the curve.
- 4
At a constrained local extremum, the contour of f is tangent to the constraint curve, which forces ∇f to be parallel to ∇G.
- 5
The Lagrange multiplier necessary condition is: find x̃ and λ such that G(x̃)=0 and ∇f(x̃)=λ∇G(x̃).
- 6
The condition also requires ∇G(x̃)≠0 so the constraint is well-behaved at the candidate point.
- 7
The Lagrange multiplier equation is necessary but not sufficient; it yields candidates that must be checked further.