Open AI Unleashes Codex AI; Powerful New Vibe Coding Agent
Based on MattVidPro's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Codex is a repository-aware software engineering agent built on the codeex-1 model, aimed at producing reviewable code changes rather than just chat responses.
Briefing
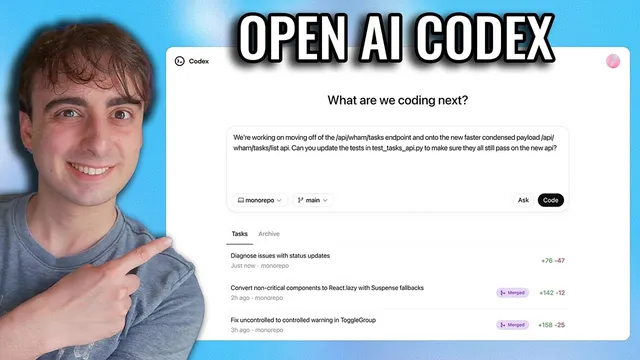
OpenAI is reintroducing Codex as a cloud-based “software engineering agent” built on the new codeex-1 model, with a key upgrade aimed at real development workflows: it can run multiple coding tasks in parallel inside isolated environments, then produce traceable, test-backed changes you can review and merge. The pitch is less about a single smarter model and more about an agentic framework plus a purpose-built interface that understands a repository—spotting issues across recent commits, editing code safely, and showing exactly what happened via terminal logs and test outputs.
Codex arrives first as a research preview inside ChatGPT (with a separate terminal-focused direction mentioned later). Users can assign work through prompts and choose between actions like “code” (make changes) and “ask” (question the codebase). Each task runs in a duplicated, sandboxed environment preloaded with the project, so failures don’t risk the original code. Inside that environment, Codex can read and edit files and execute commands, including test harnesses, linters, and type checkers—effectively acting like a crash-test facility for software. OpenAI claims typical task completion takes roughly 1 to 30 minutes, and progress can be monitored in real time. When finished, Codex commits changes in the environment and provides verifiable evidence (citations to terminal logs and test results), after which users can request revisions, open a GitHub pull request, or integrate changes locally.
A notable interface detail is how Codex can be guided by a repository file named agents.md, described as a kind of “readme for AI.” That file can instruct the agent how to navigate the codebase, which commands to run for testing, and what project standards to follow—positioning Codex to behave more like a contextual teammate than a generic code generator.
OpenAI also highlights performance and configuration details for codeex-1, including a maximum context length of 192,000 tokens and a “medium reasoning effort” setting. The company claims codeex-1 aligns more closely with human coding preferences than OpenAI o3, producing cleaner patches that are ready for immediate review, with examples suggesting o3 can be more wasteful or produce larger “blobs” of code.
Early use cases in the transcript emphasize practical developer pain points. At OpenAI, Codex is framed as a fast on-call assistant: send a stack trace, get likely fixes, and tune alerting to reduce false positives. For iOS and macOS work, Codex is used to generate scaffolding—like creating a Swift package—so engineers can start feature work sooner and run multiple tasks concurrently. Another example focuses on “paper cuts” and code-quality chores: instead of interrupting main work to fix regressions or best-practice issues, engineers can queue improvements and return later to a gradually cleaner codebase.
Access and pricing are a sticking point. Plus users reportedly lack access at first, while Pro users pay a steep jump (the transcript cites a 10x increase from Plus to Pro and mentions an $180 cost) to try the feature early. The transcript ends with the creator still waiting for access and offering a method to check eligibility via a GitHub-linked account, where Codex may appear as a button rather than in the standard model picker.
Cornell Notes
OpenAI’s Codex is a cloud “software engineering agent” built on the codeex-1 model, designed to make repository-level coding changes safely and with evidence. Instead of generating code in a single shot, Codex runs each task in an isolated environment preloaded with the project, can read/edit files, and can execute tests, linters, and type checks before committing changes. The agent supports parallel task scheduling and provides traceable outputs via terminal logs and test results, enabling review and GitHub pull requests. Codex can also be guided by an agents.md file that tells it how to navigate the codebase and which commands to run. The rollout is gated: initial access appears tied to ChatGPT Pro and may require GitHub account linking to surface the Codex option.
What makes Codex different from typical “vibe coding” chat outputs?
How does Codex keep changes safe and verifiable?
What is agents.md, and why does it matter?
What performance/configuration details were highlighted for codeex-1?
How do the transcript’s examples show Codex fitting into daily engineering work?
What access and pricing friction appears in the rollout?
Review Questions
- How does Codex’s sandboxed execution model change the risk profile compared with editing code directly in a chat session?
- Why might agents.md improve outcomes compared with relying only on a natural-language prompt?
- What evidence does Codex provide to support review, and how do test harnesses, linters, and type checkers each contribute to that evidence?
Key Points
- 1
Codex is a repository-aware software engineering agent built on the codeex-1 model, aimed at producing reviewable code changes rather than just chat responses.
- 2
Each coding task runs in an isolated, duplicated environment preloaded with the user’s codebase to reduce the chance of damaging the original project.
- 3
Codex can execute tests, linters, and type checks, then provide traceable terminal logs and test outputs as evidence for each completed task.
- 4
Tasks can be scheduled in parallel, with progress monitored in real time and changes committed in the agent environment for later review or pull requests.
- 5
An agents.md file can guide Codex on navigation, testing commands, and project standards, functioning like a “readme for AI.”
- 6
OpenAI cites typical task completion times of about 1 to 30 minutes and highlights codeex-1’s 192,000-token context window and medium reasoning effort.
- 7
Early access is gated: Pro users appear to get Codex first, while Plus users may not, with access potentially tied to GitHub account linking.