OpenAI Scholars Demo Day 2019
Based on OpenAI's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Discount factor γ in DQN can affect both intertemporal preferences and the bias/confidence of bootstrapped value estimates, so “high γ” can be harmful in dense-reward settings.
Briefing
OpenAI Scholars Demo Day 2019 showcased how machine learning research ideas—from reinforcement learning and language modeling to model compression and interpretability—can be turned into working prototypes in a short, mentored sprint. Across eight presentations, the central throughline was practical: each project tackled a concrete problem (learning from sparse signals, making decisions under uncertainty, compressing large models, or diagnosing what generative models produce) and then tested whether the approach actually improved outcomes.
One of the most technical talks focused on reinforcement learning’s discount factor, γ, in deep Q-networks (DQN). In theory, Blackwell optimality suggests that for sufficiently high γ, the same optimal policy should emerge across environments. Experiments in gridworld-style tasks complicated that picture: in sparse-reward settings, higher γ (e.g., 0.99) behaved as expected, but in dense-reward environments the highest γ performed worse than mid-range values. The proposed explanation was that γ plays a dual role: it encodes intertemporal preferences and also affects how much the algorithm “trusts” bootstrapped value estimates from function approximation—effectively weighting past information. To repair the mismatch, the project introduced a time-varying “myopic” schedule: start with a lower γ for an initial fraction of training, then ramp to the target γ. This simple change improved learning in dense environments and could still reach optimal performance in sparse environments, albeit sometimes more slowly. Follow-up experiments suggested the gains were not primarily due to extra exploration; instead, the schedule helped mitigate bias and improved convergence.
Another reinforcement learning project tackled robotics without dense external rewards by using intrinsic motivation. The method trained a dynamics model and used its prediction error as an intrinsic reward, pushing the agent toward states it hadn’t mastered yet. In OpenAI’s Fetch-style robotics environments (reaching, pushing, pick-and-place, sliding), the baseline PPO agent struggled under sparse rewards for harder tasks, while intrinsic rewards enabled rapid learning. Hyperparameter sensitivity mattered—especially the learning rate of the dynamics model—and early resets after success boosted performance. The results suggested intrinsic prediction error can act as a robust exploration bonus for real control problems.
Language-focused work included fine-tuning GPT-2 small for question answering to probe common-sense reasoning. Using datasets with both answerable and unanswerable questions (including SQuAD-style splits), the model often learned a useful abstention behavior on unanswerable items, but it showed weaknesses when answers required paraphrasing or synonym/antonym shifts. Another talk used reinforcement learning for sentiment analysis by treating word selection as a sequential decision problem, with PPO training improving over supervised-only baselines on transformer and BERT-like classifiers.
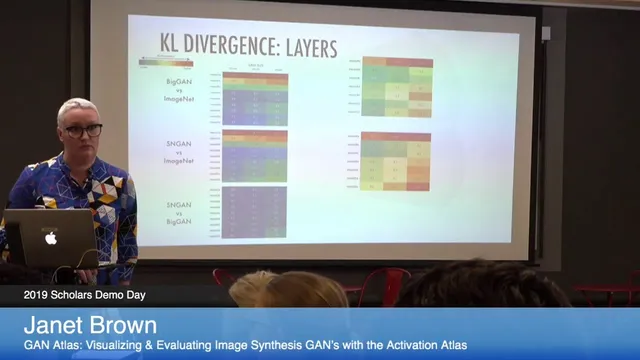
Compression and interpretability appeared as well. One scholar applied knowledge distillation to shrink transformer models, but ran into data-scale issues when storing full teacher distributions; truncating the teacher’s output to the top 10 candidate tokens reduced storage and improved results. Another project evaluated GAN quality using activation Atlas, mapping where distributions diverge inside an Inception network. Layer-by-layer visualization revealed that differences between generators and ImageNet could concentrate in later layers for some comparisons, while other divergences appeared earlier—offering a more structured way to interpret scalar GAN metrics like FID.
Finally, projects extended beyond classic benchmarks: an “AI physician” used observational EHR data to learn sepsis treatment policies with offline RL and off-policy evaluation, while an education-focused system trained BERT to recommend inquiry-based projects from web sources, then used active learning to refine topic predictions. Together, the day’s demos argued—through results, not just ideas—that careful problem framing plus targeted experiments can turn advanced ML concepts into usable prototypes quickly.
Cornell Notes
OpenAI Scholars Demo Day 2019 highlighted multiple ML prototypes built in a short, mentored timeframe, with a strong emphasis on turning theory into measurable behavior. In deep RL, discount factor γ was shown to have a dual role in DQN—preferences over time and implicit confidence in bootstrapped value estimates—leading to failures of Blackwell optimality in dense-reward settings. A time-varying “myopic” γ schedule (start lower, ramp up) improved dense-environment learning and could still reach optimal performance in sparse tasks. In robotics, intrinsic motivation via dynamics-model prediction error produced dense internal rewards that enabled sparse-reward agents to solve harder Fetch tasks. Across language and generative modeling, work ranged from GPT-2 fine-tuning for QA abstention to knowledge distillation for smaller transformers and activation-Atlas-based GAN evaluation.
Why did high discount factors (e.g., γ=0.99) fail in dense-reward DQN experiments, even though Blackwell optimality would suggest otherwise?
What is the “myopic” γ schedule, and how did it change learning outcomes?
How did intrinsic motivation work for sparse-reward robotics tasks in the Fetch environments?
What did the GPT-2 small QA fine-tuning reveal about common-sense reasoning and model behavior?
How did knowledge distillation run into practical issues, and what fix improved results?
What did activation Atlas add beyond scalar GAN metrics like FID?
Review Questions
- In DQN, what two roles does γ play in the proposed explanation for dense-reward failures, and how does the myopic schedule address them?
- For intrinsic motivation in robotics, why does prediction error from a learned dynamics model encourage exploration, and what hyperparameter was especially important?
- When fine-tuning GPT-2 small for QA, what kinds of answer transformations (e.g., paraphrases) tended to cause failures, and how did the model behave on unanswerable questions?
Key Points
- 1
Discount factor γ in DQN can affect both intertemporal preferences and the bias/confidence of bootstrapped value estimates, so “high γ” can be harmful in dense-reward settings.
- 2
A time-varying myopic γ schedule (start lower, ramp to target) can restore learning quality without needing to search for a single best fixed γ.
- 3
Intrinsic motivation via dynamics-model prediction error can turn sparse external rewards into dense internal rewards, enabling harder robotics tasks to be solved with PPO.
- 4
In robotics experiments, the dynamics model learning rate and early reset strategy materially influenced success rates and convergence speed.
- 5
Knowledge distillation can fail in practice when storing full teacher distributions creates unmanageable data volumes; truncating teacher outputs to top candidates can make training feasible.
- 6
Activation Atlas provides interpretability for generative models by localizing distribution differences inside a classifier network rather than relying on a single scalar score.
- 7
Offline RL for medical decision-making requires careful state/action discretization and off-policy evaluation (e.g., weighted importance sampling) because data come from observational behavior policies.