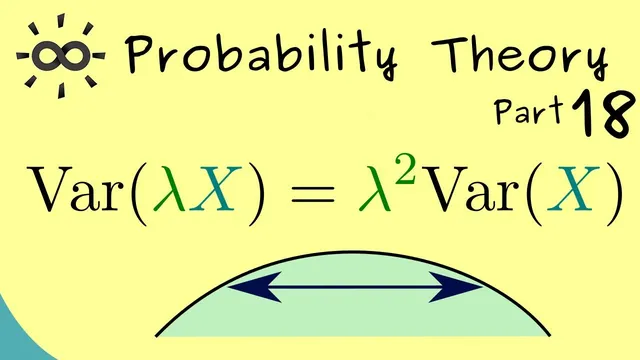
Probability Theory 18 | Properties of Variance and Standard Deviation
Based on The Bright Side of Mathematics's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Variance is defined as Var(Z)=E[Z²]−(E[Z])², so E[Z²] must be finite for the variance to exist.
Briefing
Variance and standard deviation behave predictably under addition and scaling—provided the random variables involved are independent and the relevant second moments are finite. For two independent random variables X and Y with well-defined variances, the variance of their sum is additive: Var(X + Y) = Var(X) + Var(Y). Scaling is also simple: for any real number λ, Var(λX) = λ² Var(X). These rules matter because they let you compute uncertainty for combined or rescaled random quantities without re-deriving everything from scratch.
The transcript also clarifies the corresponding rule for standard deviation, including the subtle absolute value that appears when taking square roots. Since standard deviation is defined as the square root of variance, σ(X) = √Var(X), the scaling rule becomes σ(λX) = |λ| σ(X). The absolute value is necessary because standard deviation is always nonnegative, so negative scaling factors cannot produce negative spread.
To justify the addition formula, the discussion starts from the definition of variance in terms of expectations: Var(Z) = E[Z²] − (E[Z])². For Var(X + Y), the square inside the expectation expands to X² + 2XY + Y². Linearity of expectation then separates terms into E[X²] + 2E[XY] + E[Y²]. The second part of the variance formula, (E[X + Y])², expands to (E[X] + E[Y])² = (E[X])² + 2E[X]E[Y] + (E[Y])². When subtracting these expressions, the E[X²] − (E[X])² terms combine into Var(X), and the E[Y²] − (E[Y])² terms combine into Var(Y). What remains is a cross-term: 2(E[XY] − E[X]E[Y]).
Independence is the key step that kills that cross-term. With independent X and Y, E[XY] equals E[X]E[Y], making E[XY] − E[X]E[Y] = 0. That leaves exactly Var(X + Y) = Var(X) + Var(Y). The transcript then handles the scaling rule similarly but with only one variable: Var(λX) = E[(λX)²] − (E[λX])². Using linearity and the fact that (λX)² = λ²X², both expectation terms pick up a factor of λ², which factors out to yield Var(λX) = λ² Var(X).
Finally, the standard deviation rule follows immediately by taking square roots: σ(λX) = √Var(λX) = √(λ² Var(X)) = |λ| √Var(X) = |λ| σ(X). The overall takeaway is a set of practical, calculation-ready identities for variance and standard deviation under independence and scaling, grounded directly in the expectation-based definition of variance and the multiplicative property of expectations for independent random variables.
Cornell Notes
Variance and standard deviation follow clean algebraic rules when second moments exist and the variables are independent. For independent random variables X and Y, Var(X + Y) = Var(X) + Var(Y). For any real scalar λ, Var(λX) = λ² Var(X). Because standard deviation is the square root of variance, the scaling rule becomes σ(λX) = |λ| σ(X), where the absolute value ensures nonnegativity. These identities come straight from Var(Z) = E[Z²] − (E[Z])², plus linearity of expectation and the independence fact E[XY] = E[X]E[Y].
Why does Var(X + Y) become Var(X) + Var(Y) only when X and Y are independent?
How does the definition of variance lead to the additive rule for independent sums?
Why does scaling variance by λ produce λ², not λ?
Where does the absolute value appear in σ(λX)=|λ|σ(X)?
What conditions must hold for these variance and standard deviation formulas to be valid?
Review Questions
- Given Var(Z)=E[Z²]−(E[Z])², derive Var(X+Y) and identify the term that disappears under independence.
- Compute σ(−3X) in terms of σ(X) and explain why the result uses an absolute value.
- If X and Y are not independent, which expectation term prevents Var(X+Y) from simplifying to Var(X)+Var(Y)?
Key Points
- 1
Variance is defined as Var(Z)=E[Z²]−(E[Z])², so E[Z²] must be finite for the variance to exist.
- 2
For independent random variables X and Y, Var(X+Y)=Var(X)+Var(Y).
- 3
Scaling a random variable by a real number λ scales variance by λ²: Var(λX)=λ²Var(X).
- 4
Standard deviation is the square root of variance, so σ(λX)=|λ|σ(X).
- 5
The additive variance rule relies on the independence identity E[XY]=E[X]E[Y], which cancels the cross-term.
- 6
Linearity of expectation is used repeatedly to expand and regroup terms when computing variances.