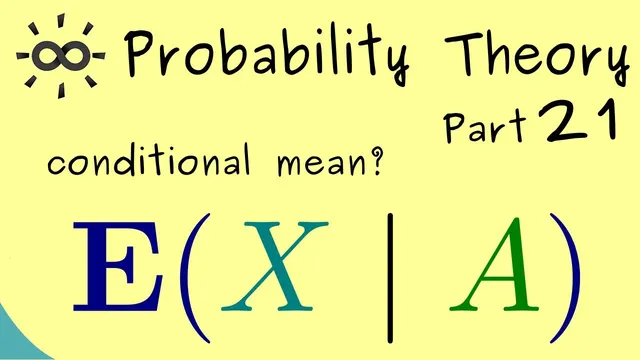
Probability Theory 21 | Conditional Expectation (given events)
Based on The Bright Side of Mathematics's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Conditional probability renormalizes probabilities inside an event B using P(A | B) = P(A ∩ B)/P(B), requiring P(B) > 0.
Briefing
Conditional expectation given an event is built by reweighting probabilities so that only outcomes inside the conditioning event matter. If an event B has nonzero probability, the conditional probability measure rescales probabilities by the ratio P(A ∩ B)/P(B), turning “probability inside B” into a proper probability law. Expectations then follow the same pattern: the conditional expectation of a random variable X given B is just the ordinary expectation computed under this new, renormalized probability measure.
A key practical takeaway is that conditional expectation can be computed without changing the measure explicitly. Using indicator functions, the conditional expectation E[X | B] can be rewritten as a scaling factor 1/P(B) times an ordinary expectation of X multiplied by the indicator 1_B (which equals 1 on B and 0 outside). Concretely, this turns the problem into integrating (or summing) X over the region where B holds, with the original probability measure providing the weighting. This “indicator = restrict the domain” viewpoint is the bridge between abstract definitions and hands-on calculations.
In the continuous example, X is standard normal with density f(x) = (1/√(2π)) e^{-x^2/2}. The conditioning event is B = {X > 0}, which selects only the right half of the distribution. Because a standard normal is symmetric, P(B) = 1/2, so the scaling factor becomes 2. The conditional expectation reduces to an integral of x times the normal density over (0, ∞). Evaluating the resulting expression yields E[X | X > 0] = 2/√(2π). The result is positive—exactly what intuition predicts since only positive outcomes are allowed.
The transcript also highlights a general identity: when the random variable is an indicator 1_A, the conditional expectation E[1_A | B] matches the conditional probability P(A | B). In other words, conditional probability can be expressed as a conditional expectation, reinforcing that both concepts are the same renormalization idea viewed through different lenses.
Finally, the discrete example uses a fair die. Let X be the face value, and condition on B = {5, 6}. Under this restriction, the conditional distribution assigns probability 1/2 to each of 5 and 6. The conditional expectation becomes (5·(1/2) + 6·(1/2)) = 11/2 = 5.5. The calculation makes the meaning concrete: conditional expectation is simply the average of X after discarding all outcomes outside B and renormalizing the remaining probabilities.
Overall, conditional expectation given an event is a systematic way to compute averages under “knowledge that B occurred,” implemented by renormalizing probabilities and, in practice, by integrating or summing X over the event region using indicator functions.
Cornell Notes
Conditional expectation given an event B is the ordinary expectation computed under the renormalized probability measure that only counts outcomes in B. When P(B) > 0, the conditional probability is P(A | B) = P(A ∩ B)/P(B), and the conditional expectation E[X | B] is defined as the expectation of X with respect to that conditional probability measure. A practical formula rewrites it using an indicator: E[X | B] = (1/P(B)) · E[X · 1_B], so the indicator effectively restricts the domain of integration/summation to where B holds. Examples show the method works for both continuous and discrete cases: for a standard normal conditioned on X > 0, the result is 2/√(2π); for a die conditioned on {5,6}, the result is 5.5.
How does conditional probability lead to conditional expectation?
Why does the indicator function 1_B matter for calculations?
What is the continuous example result, and how is it obtained?
How does the discrete die example work under conditioning?
What special relationship connects conditional probability and conditional expectation?
Review Questions
- Given an event B with P(B) > 0, write the formula for E[X | B] using an indicator function.
- For a symmetric continuous distribution, what does conditioning on {X > 0} do to P(B) and the scaling factor in E[X | B]?
- In the die example conditioned on {5,6}, what conditional probabilities are assigned to 5 and 6, and how do they determine E[X | B]?
Key Points
- 1
Conditional probability renormalizes probabilities inside an event B using P(A | B) = P(A ∩ B)/P(B), requiring P(B) > 0.
- 2
Conditional expectation E[X | B] is the ordinary expectation of X computed under the conditional probability measure.
- 3
A computation shortcut is E[X | B] = (1/P(B)) · E[X · 1_B], where the indicator 1_B restricts contributions to outcomes in B.
- 4
For continuous variables, conditioning turns the expectation integral into one over the region defined by B (with the same original density).
- 5
For discrete variables, conditioning turns the expectation into a weighted average over only the outcomes in B, with probabilities renormalized.
- 6
Conditional probability is a special case of conditional expectation: E[1_A | B] = P(A | B).