Probability Theory 32 | De Moivre–Laplace theorem
Based on The Bright Side of Mathematics's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
A binomial random variable counts successes in n independent Bernoulli trials with success probability p.
Briefing
The De Moivre–Laplace theorem turns the binomial distribution into an (asymptotically) normal one, giving a practical way to approximate binomial probabilities with the familiar bell curve from the central limit theorem. The key idea is that when a binomial random variable comes from many independent Bernoulli trials, its distribution becomes increasingly bell-shaped as the number of trials grows—especially near its mean.
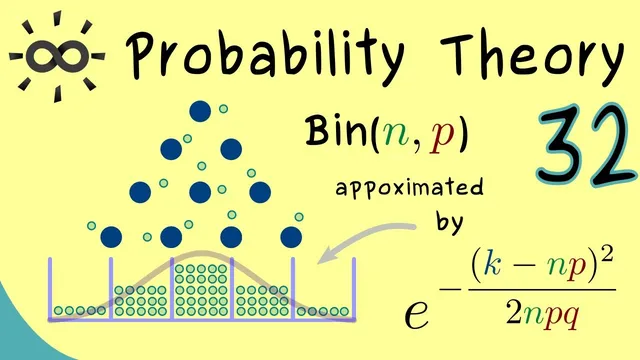
A binomial distribution counts the number of “successes” in n repeated Bernoulli (coin-toss) experiments, where each trial succeeds with probability p and fails with probability 1−p. In the transcript’s coin-toss picture, each bead falling into a column corresponds to a particular count K of successes, with K ranging from 0 to n. The exact probability mass function is
P(X=K)=\binom{n}{K} p^K (1−p)^{n−K}.
For small n, the distribution is discrete and can be computed directly. But as n increases, histograms built from repeated simulations start to resemble a continuous bell curve, motivating the approximation: instead of wrestling with binomial coefficients, one can use the normal distribution’s density.
The normal approximation uses the mean and variance of the binomial: mean n·p and variance n·p(1−p). The transcript presents the approximate probability (for K near the middle) as matching the normal density up to the correct scaling factor. Concretely, the approximation takes the form
P(X=K) ≈ \frac{1}{\sqrt{2\pi n p(1−p)}}\exp\left(-\frac{(K−n p)^2}{2 n p(1−p)}\right).
This is the practical De Moivre–Laplace message: for large n and K close to the expected value n·p, binomial probabilities behave like normal probabilities.
To move beyond a hand-wavy match of shapes, the transcript describes a more precise limiting statement. The normal approximation is justified by comparing the binomial pmf to the normal pdf (with the appropriate standardization). The ratio of the two quantities approaches 1 as n→∞, meaning the difference between the discrete binomial probability and the continuous normal density becomes negligible in the relevant region.
That “relevant region” matters: K must stay near the mean. In the limit formulation, the exponent term in the normal expression must remain bounded—equivalently, (K−n p)^2 is controlled relative to n p(1−p). Under these conditions, after shifting and scaling (the same standardization used in the central limit theorem), the binomial distribution converges pointwise to the standard bell curve.
Finally, the theorem’s assumptions exclude the degenerate endpoints p=0 and p=1, requiring 0<p<1. With that, the De Moivre–Laplace theorem becomes a named, historically important special case of the central limit theorem: it formalizes when and how binomial probabilities can be replaced by normal ones for computation and approximation.
Cornell Notes
The De Moivre–Laplace theorem provides a normal approximation to the binomial distribution. For X~Bin(n,p), the exact probability P(X=K)=C(n,K)p^K(1−p)^{n−K} becomes well-approximated by a normal density when n is large and K stays near the mean n·p. The approximation uses the binomial’s mean n·p and variance n·p(1−p), yielding P(X=K)≈[1/√(2πn p(1−p))]·exp(−(K−n p)^2/(2n p(1−p))). A more precise version compares the binomial pmf to the normal pdf via a ratio that tends to 1 as n→∞, provided the exponent stays bounded (i.e., K is not far from the mean). The result requires 0<p<1.
How does a binomial distribution arise from repeated experiments, and what do n, p, and K represent?
What exact formula is used for binomial probabilities before any approximation?
What normal distribution parameters match the binomial distribution’s shape near the mean?
When is the approximation accurate, and why does K need to be near n·p?
How does the theorem make the approximation precise instead of just comparing shapes?
What restriction on p is required for the theorem to apply?
Review Questions
- For X~Bin(n,p), write the exact expression for P(X=K) and identify the mean and variance used in the normal approximation.
- State the conditions on K (relative to n·p) under which the binomial-to-normal approximation is justified.
- In the precise formulation, what does it mean for the ratio of the binomial pmf to the normal pdf to approach 1 as n→∞?
Key Points
- 1
A binomial random variable counts successes in n independent Bernoulli trials with success probability p.
- 2
The exact binomial probability is P(X=K)=\binom{n}{K} p^K (1−p)^{n−K}, but it becomes cumbersome for large n.
- 3
For large n and K near the mean n·p, binomial probabilities are well-approximated by a normal density.
- 4
The normal approximation uses mean n·p and variance n·p(1−p), producing the factor 1/√(2πn p(1−p)) and exponent −(K−n p)^2/(2n p(1−p)).
- 5
A more rigorous statement compares the binomial pmf to the normal pdf via a ratio that tends to 1 as n→∞.
- 6
The approximation is justified only in a neighborhood of the mean, expressed by keeping the normal exponent bounded.
- 7
The theorem assumes 0<p<1, excluding the degenerate cases p=0 and p=1.