Programming with LLM Agents in 2025
Based on sentdex's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Open Hands is treated as a structured loop (prompting plus conditional logic), so success comes from engineering discipline rather than expecting “magic.”
Briefing
Programming with LLM agents in 2025 is less about “magic” and more about turning large-model output into a reliable engineering workflow: break problems into small steps, keep state organized, and let an agent iterate on code and experiments while a human focuses on direction and validation. A practical example centers on Open Hands—an agentic layer that behaves like a structured loop (prompting plus conditional logic) rather than a mysterious new kind of intelligence. With it, a developer can upload a dataset, ask for preprocessing and training scripts, and then repeatedly refine an experiment without writing most of the glue code by hand.
The walkthrough starts by installing Open Hands via two commands, then configuring an API key (the example uses Anthropic) and selecting a coding-capable model (Claude 3.5 is mentioned). The agent’s workflow is demonstrated through a small R&D project: using Shakespeare text as training data to evolve a binary-encoded neural model that predicts encoded characters. Instead of attempting a single, massive “do everything” prompt, the process is intentionally decomposed: first generate preprocessing code that converts the text into bit-level training samples (15 input characters to 3 output characters), then create an experiment scaffold, and finally iterate on the evolutionary algorithm and neural architecture.
A key operational tactic is maintaining a workspace-level README.md that summarizes goals, completed steps, and a to-do list. As the agent runs, context can balloon and degrade performance; the README acts as a compact source of truth so the agent can reset cleanly after a certain number of steps. The transcript also emphasizes practical engineering discipline: long-running scripts need debugging output (console logs or JSON artifacts), and test cases should be saved so the agent can iterate toward measurable success instead of wandering.
On the modeling side, the experiment uses an evolutionary approach (with NEAT referenced as a library option) to evolve network structure and parameters. The agent iterates on design choices like hidden layers, mutation operations (adding/removing nodes and layers), fitness evaluation, and activation functions. When results stall around ~50% average fitness, the workflow shifts toward diagnosing why—adding sigmoid/tanh activations, adjusting weight initialization to prevent saturation, improving the fitness function to reward partial matches, and experimenting with architectural tweaks such as skip connections. The experiment eventually reaches a higher best fitness (reported around the mid-70% range) and begins producing more plausible encoded outputs.
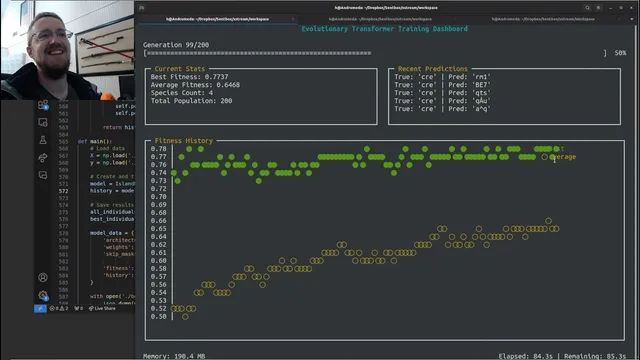
The most striking payoff is not a new breakthrough model, but the leverage: the human provides high-level instructions while multiple agent tasks can run in parallel, yielding a claimed ~10x speedup per agent and potentially far more with several agents running simultaneously. The transcript culminates in “bonus content” where the agent generates a live training dashboard using curses—rendering fitness history in an interactive terminal UI. The developer then asks for improvements like line graphs, labeled axes, and full-history plotting, reinforcing the theme that agents can automate not just training code but also the instrumentation needed to understand experiments.
Overall, the core message is that agents work best when treated like junior engineers inside a controlled workflow: decompose tasks, maintain state, require debuggable outputs, and iterate with measurable checkpoints. The result is faster experimentation and richer feedback loops—without needing to hand-code every detail.
Cornell Notes
LLM agents in 2025 can accelerate coding and R&D when they’re used like structured iterators rather than “one-shot” problem solvers. The example uses Open Hands to run an evolutionary-training experiment on Shakespeare text: the agent generates preprocessing code, builds training scripts, and iteratively refines model architecture and fitness evaluation. A README.md in the workspace becomes the compact source of truth so context can be reset without losing the experiment’s state. The workflow also stresses engineering basics—debug logs, JSON outputs for analysis, and test cases—because long runs and complex code still require validation. The payoff includes a live curses dashboard that visualizes best and average fitness over generations, making progress easy to monitor and steer.
Why does the transcript insist on breaking work into smaller prompts instead of one huge instruction?
What role does README.md play in keeping an agent-driven project stable?
How does the experiment diagnose “stuck” learning around ~50% average fitness?
What engineering practices are emphasized for long-running agent-generated scripts?
What makes the curses dashboard a meaningful “agent win” rather than just a UI flourish?
How does parallelism change the productivity equation for agent workflows?
Review Questions
- What specific mechanisms in the workflow prevent context from degrading agent performance over many steps?
- How do changes to activation functions and fitness evaluation alter the learning behavior in the evolutionary experiment?
- Why is debug output (console logs/JSON artifacts) critical when agent-generated scripts run for long periods?
Key Points
- 1
Open Hands is treated as a structured loop (prompting plus conditional logic), so success comes from engineering discipline rather than expecting “magic.”
- 2
Decompose tasks into subproblems (preprocessing → training scaffold → evolutionary loop → fitness/architecture tweaks) instead of issuing one massive instruction.
- 3
Maintain a workspace README.md as a compact experiment state so the agent can reset without losing goals or file context.
- 4
Require debuggable outputs: console logs and JSON artifacts for progress and analysis, especially for long-running training or benchmarking.
- 5
Use measurable checkpoints (fitness trends, test cases, saved artifacts) to guide iteration and avoid aimless wandering.
- 6
Evolutionary training benefits from targeted changes when learning stalls: activation functions, weight scaling, bias terms, and fitness functions that reward partial matches.
- 7
Agent leverage increases with parallelism: multiple agents can run experiments and tooling simultaneously while the human focuses on direction and validation.