Progressive Elaboration - Self-Publishing 4D PKM in 6 Weeks - VLOG Episode 5
Based on Zsolt's Visual Personal Knowledge Management's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
The author reached 35,853 words in an AI-assisted first draft but found that long prompts often produce text that reads well locally while failing to align globally.
Briefing
A self-publishing sprint is turning into a workflow lesson: writing a full book with GPT works best when drafts are generated in small, connected units—then stitched together using “progressive elaboration” rather than trying to produce long, cohesive chapters in one pass. After roughly 20 hours of weekend writing, the author had reached 35,853 words in an AI-assisted first draft, but the text quality exposed a practical bottleneck: large prompts often produced good snippets that failed to align with each other, leaving gaps in chapter-to-chapter cohesion.
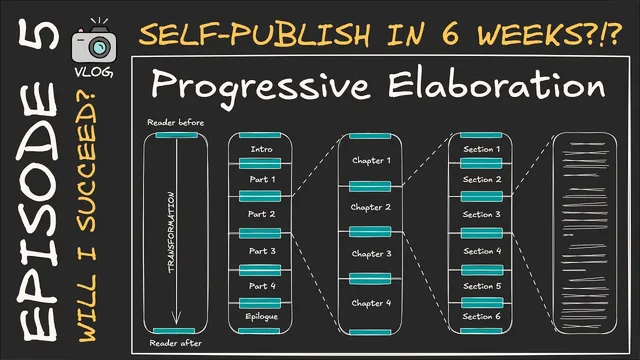
The process began with a reader-centered transformation map. The author defined who the reader is at the start and who they become by the end, then created multiple reader “types” with paired paragraphs for each. From that foundation came a detailed outline: an intro, multiple parts, an epilog, and chapters broken down into sections and bullet points—an outline that ballooned to about 10,000 words at the section level. Feeding that outline into GPT produced engaging prose, but not consistently cohesive long-form output.
The key constraint was scale. When GPT was asked to generate an entire chapter—roughly 3,000 to 4,000 words—the model struggled to maintain cohesion and the author found performance dropped sharply beyond around 8,000 words of generated material. Even when the text was later expanded in an editor, it rarely exceeded about 1,500 words reliably. The workaround—generating chapters section by section—solved the length problem but introduced a new one: each section read well on its own while the chapter’s internal continuity and overall narrative “fit” suffered.
To fix that, the author redesigned the prompt structure around transitions. For each major book segment (intro parts 1–4 and the epilog), GPT was tasked with producing three anchor statements: an opening paragraph, a closing paragraph, and a transformation description tied to that segment’s objective. Those anchors were then “exploded” downward: GPT used the segment-level transformation and outline to generate chapter-level opening/closing paragraphs and chapter content descriptions, and then repeated the same pattern at the section level. By giving GPT recurring context—stored in the opening and closing frames—it produced text that matched more naturally across boundaries, even if “rough edges” still remained and would require manual cleanup after a full draft read-through.
The author’s immediate plan is to finish the remaining parts quickly but not recklessly: complete part four and the epilog within the next few days, then take a holiday reading pass to mark inconsistencies and rough spots. Notes will be converted back into the draft with GPT, followed by a second read to tighten the final version. The goal is self-publishing by March 15, paired with a proper launch rather than a rushed release that could undermine sales. Alongside the writing workflow, the author also shared cover art experiments, weighing a more vibrant, engaging design against a cleaner, more focused alternative—seeking feedback on which better matches the book’s heart.
Cornell Notes
The author’s AI-assisted book draft hit a common long-form problem: GPT can generate engaging sections, but large prompts often fail to produce cohesive chapters that “fit” together. The weekend work reached 35,853 words, yet the text quality revealed that section-by-section generation improves output length but can break continuity. The solution is “progressive elaboration,” a reverse of progressive summarization: create reader transformation anchors at the part level (opening, closing, and transformation), then propagate those anchors to chapters and sections so each unit has enough context to align. The remaining work is manual cleanup after a full read-through, followed by another GPT-assisted revision pass to smooth rough edges before a March 15 self-publishing deadline.
Why did generating whole chapters in one GPT pass underperform, even when individual sections looked strong?
How does “progressive elaboration” differ from “progressive summarization,” and what does it practically do?
What role did the reader transformation map play in the writing workflow?
What was the author’s “stitching” mechanism to restore cohesion after switching to section-by-section generation?
What risks remain even after progressive elaboration, and how will they be handled?
Review Questions
- What specific failure mode occurred when GPT was prompted to generate entire chapters, and how did the author measure or observe it?
- Describe the three anchor elements created for each part in progressive elaboration and explain how they propagate to chapters and sections.
- Why does section-by-section generation improve output length but threaten cohesion, and what mechanism counteracts that threat?
Key Points
- 1
The author reached 35,853 words in an AI-assisted first draft but found that long prompts often produce text that reads well locally while failing to align globally.
- 2
GPT’s chapter-length generation struggled with cohesion and reliability, with performance dropping beyond about 8,000 words of generated material and expansions rarely exceeding roughly 1,500 words.
- 3
Switching to section-by-section drafting fixed the length problem but introduced continuity gaps between sections and chapters.
- 4
Progressive elaboration improves fit by creating part-level anchor frames—opening paragraph, closing paragraph, and transformation description—and reusing them at chapter and section levels.
- 5
A reader transformation map (reader state at the start vs. end, with multiple reader types) anchors the outline and guides what each generated unit should accomplish.
- 6
The workflow still requires manual cleanup after a full draft read-through to remove “rough edges” and smooth inconsistencies.
- 7
The schedule targets self-publishing by March 15 while prioritizing a proper launch over rushing the draft quality.