Project Structure (1) - Testing & Deployment - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
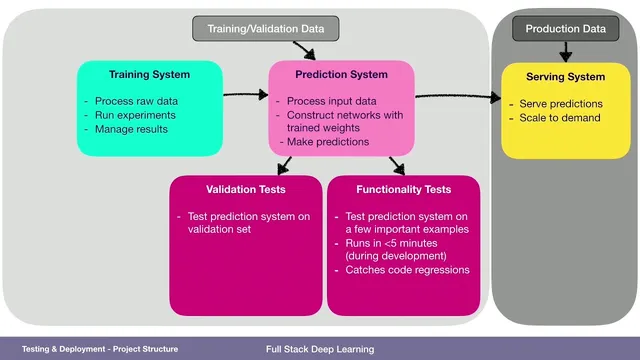
Separate the prediction system (input processing + trained weights + decision logic) from the training system (experiments and pipeline execution) and the serving system (scalable deployment of predictions).
Briefing
A practical full-stack deep learning setup hinges on separating three systems—prediction, training, and serving—and then testing each with the right kind of data at the right speed. The prediction system is more than TensorFlow or PyTorch code: it includes input-processing logic, the trained network weights, and any decision layer such as confidence thresholds that turn model outputs into final predictions. The training system then takes raw data, runs experiments, and produces the prediction system, while the serving system deploys it to production where it can scale with demand.
That separation matters because the data used during development is not the same as the data the model will face in production. Training and validation data feed the training system to generate the prediction system, but production time brings a fresh dataset the team cannot see in advance. Serving therefore becomes the place to test the end-to-end arrangement against “production-like” inputs—at least indirectly—through a testing and monitoring strategy.
Testing is organized into three layers with different goals and time budgets. Functionality tests target the prediction system’s correctness on a small set of high-importance examples, ideally running in under five minutes so regressions get caught quickly as code changes. These tests should start from the same form of data the system will actually see in production—for an image model, that means real images rather than preprocessed placeholders. Validation tests broaden coverage by running the prediction on a much larger validation set—potentially millions of examples—using a form of data that may be preloaded (like a data frame with images already attached). The aim is to detect performance regressions every time code is pushed, with an expected runtime of minutes to hours.
Training-system tests focus on the entire pipeline, from the rawest possible data through preprocessing and training, because upstream changes can silently break results. These tests may take longer—up to a day—so they can run daily. They’re designed to catch issues such as data-source changes or dependency upgrades that alter data formatting. For example, a TensorFlow upgrade might not matter if only pandas changed; the model might still be trained on subtly different data next time, and only a full training pipeline test using production-like inputs would reliably surface that.
Finally, the workflow distinguishes testing from monitoring. Monitoring aims to detect failures in production—service downtime, runtime errors, and shifts in the distribution of incoming data—so the team can respond when the real world diverges from training assumptions. Together, fast functionality tests, broader validation tests, full-pipeline training tests, and ongoing monitoring form a cohesive defense against both code regressions and service/data regressions.
Cornell Notes
The system design for full-stack deep learning splits responsibilities across a prediction system, a training system, and a serving system. The prediction system includes input processing, trained weights, and decision logic like confidence thresholds. Training and validation data generate the prediction system, but serving must handle production data the team cannot pre-check. Testing is staged: functionality tests run quickly (under ~5 minutes) on a small set of production-form examples to catch code regressions; validation tests run in minutes to hours on much larger datasets to detect performance drops; training-system tests run daily (up to ~1 day) to catch upstream regressions from data-source or dependency changes. Monitoring then covers what tests can’t: production failures and data distribution shifts.
What exactly counts as the “prediction system,” beyond the neural network code?
Why can’t production data be treated the same way as training/validation data?
How do functionality tests differ from validation tests in both data and runtime goals?
What is the purpose of training-system tests, and why do they take longer?
Why does monitoring complement testing instead of replacing it?
Review Questions
- How would you choose the data format for functionality tests so they best reflect what serving will actually receive?
- What kinds of changes are most likely to slip past functionality/validation tests but get caught by full training-system tests?
- What signals in monitoring would indicate a service regression versus a data regression?
Key Points
- 1
Separate the prediction system (input processing + trained weights + decision logic) from the training system (experiments and pipeline execution) and the serving system (scalable deployment of predictions).
- 2
Use training and validation data to build the prediction system, but assume production will bring unseen data that must be handled by serving and monitored in production.
- 3
Run functionality tests on a small set of high-importance examples using production-form inputs, aiming for runtimes under about five minutes to catch code regressions quickly.
- 4
Run validation tests on much larger datasets (potentially millions of examples) to detect performance regressions, targeting runtimes of minutes to hours.
- 5
Test the training pipeline end-to-end with raw data in daily training-system tests (up to about a day) to catch upstream regressions from data-source changes or dependency upgrades.
- 6
Treat monitoring as a distinct layer that detects production failures (downtime, errors) and data distribution shifts that tests can’t fully anticipate.
- 7
Design the overall workflow so each test layer has a clear purpose and a realistic time budget aligned with how often it can run.