Project Walkthrough: askFSDL (LLM Bootcamp)
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
askFSDL’s answer quality improves most from ETL decisions: preserving source structure and chunking text to match retrieval needs, not from model swaps alone.
Briefing
A Discord bot built for askFSDL delivers retrieval-augmented question answering over a curated knowledge base, but the biggest gains come less from swapping models and more from doing careful data engineering—preserving document structure, extracting the right text, and chunking it in a way that matches how answers are sourced.
At the core, the system uses vector storage for retrieval: user questions are matched against embedded sources, and the retrieved snippets are inserted into a LangChain prompt template to drive a “zero-shot” style response. The project is organized as a multi-service codebase with a document database (MongoDB via Atlas in this walkthrough), a vector index, and a backend deployed on Modal. A Makefile ties together the setup steps—Discord bot configuration, backend deployment, and vector index creation—so the moving parts can be run consistently.
The walkthrough contrasts an early, “bare minimum” pipeline—scrape data, chunk it, embed it—with a more deliberate ETL approach that improves answer quality. For PDFs and other documents, the key lesson is that treating everything as plain text can destroy structure that matters for navigation and sourcing. When ingesting content from the Full Stack Deep Learning site (including markdown-rich lecture notes), preserving elements like section headers and paragraph boundaries helps the system link answers back to the right parts of pages. The same theme shows up with YouTube: transcripts are available for free, but the default subtitle timing is too granular (one-second segments). The fix is to re-chunk transcripts into larger, token-meaningful blocks—often on the order of hundreds to a couple thousand tokens—so retrieval returns coherent context rather than fragments.
Beyond data, the project emphasizes software engineering hygiene to keep a team’s codebase stable. It uses GitHub pre-commit checks to catch common mistakes before commits, applies Black for consistent Python formatting, and relies on linting (previously flake8, with a shift toward Ruff, a Rust-powered formatter/linter). For shell scripts, ShellCheck helps prevent typical bash errors. These tools reduce friction when dependencies and transitive versions would otherwise conflict.
The second half shifts to infrastructure and developer workflow. Modal is positioned as the solution for running many isolated tasks without the overhead of slow container builds and deployments. The architecture follows an ETL pattern—extract from web or internal storage, transform into retrieval-ready documents, then load into the document store—while Modal containers handle concurrency via mapping functions (including controlling maximum parallelism). Modal also provides serverless endpoints, GPU support when needed, and an ASGI-based application layer.
For the user interface layer, the bot’s interactions are served through Discord, while Modal’s Radio framework is highlighted as a Python-first way to build quick UIs without learning JavaScript. Radio can be embedded for demos and supports an OpenAPI-style integration path.
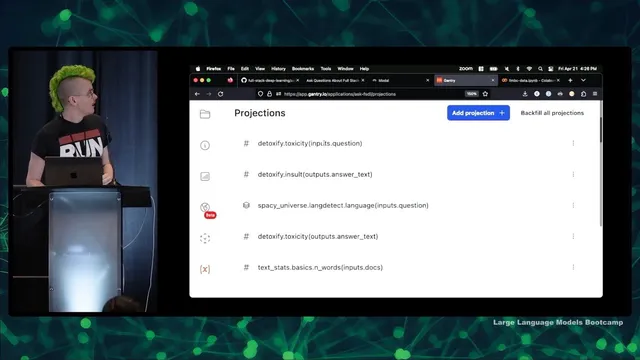
Finally, production readiness is treated as an observability problem. The system logs model inputs/outputs to Gantry, enabling later enrichment such as toxicity checks, entropy and sentence-count projections, and other analytics. Logged conversations can also be re-evaluated with LLM-based graders (using LangChain and a ChatGPT model) to flag whether answers are “reasonable.” The remaining challenge is not just improving retrieval or output quality, but building a sustainable user base—something the team plans to tackle after the technical foundation is stronger.
Cornell Notes
askFSDL is a Discord bot for retrieval-augmented Q&A over a curated corpus. The biggest quality improvements come from ETL choices: preserving document structure (especially markdown-derived lecture notes), extracting the right text, and chunking sources so retrieval returns coherent context. YouTube transcripts work well, but one-second subtitle segments are too small; re-chunking into hundreds-to-thousands of tokens improves answer quality. The system uses vector retrieval with embeddings, inserts retrieved sources into a LangChain prompt template, and serves the app through Modal infrastructure. Production monitoring relies on Gantry logging and enrichment, plus optional LLM-based grading to assess whether answers are reasonable.
Why does preserving document structure matter more than simply embedding “raw text” from sources like markdown lecture notes?
What specific change improved YouTube-based sourcing, and why did it help retrieval?
How does the system connect retrieval results to the final answer generation step?
What role does Modal play beyond “running code,” according to the walkthrough?
Why are code-quality tools (pre-commit, Black, Ruff, ShellCheck) treated as essential in this project?
How does the project evaluate and monitor model behavior after deployment?
Review Questions
- What ETL failure mode occurs when markdown or structured notes are ingested as plain text, and how does preserving structure mitigate it?
- Explain how chunk size affects retrieval quality for time-tagged transcripts, using the YouTube example.
- What kinds of post-deployment signals does Gantry enable, and how can LLM-based grading complement those logs?
Key Points
- 1
askFSDL’s answer quality improves most from ETL decisions: preserving source structure and chunking text to match retrieval needs, not from model swaps alone.
- 2
Markdown-derived lecture notes should retain semantic structure (headers/paragraphs) so retrieval can point to the right page components.
- 3
YouTube transcripts require re-chunking; one-second subtitle segments are too fine-grained for effective retrieval.
- 4
Vector retrieval is integrated with LangChain by inserting retrieved sources into a prompt template alongside the user question.
- 5
Modal supports concurrent ETL and serverless backend execution, with fast interactive debugging via an IPython kernel in the cloud environment.
- 6
Codebase stability is supported by pre-commit checks, Black formatting, Ruff linting/formatting, and ShellCheck for bash scripts.
- 7
Production monitoring relies on Gantry logging plus enrichment (toxicity, entropy, etc.) and optional LLM-based “reasonable answer” grading.