Quantifying Interpretability of Models Trained on Coi… | Jorge Orbay | OpenAI Scholars Demo Day 2020
Based on OpenAI's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Interpretability is treated as a measurable proxy for how much a model’s decision-relevant signals align with human-recognizable objects, rather than as a purely qualitative judgment.
Briefing
Neural networks trained on more diverse experience tend to develop features humans can interpret more often—and that relationship can be measured without relying entirely on slow human review. In a Scholars Demo Day 2020 project built on CoinRun (a Mario-style platformer), Jorge Orbay frames interpretability as “mind reading” for models: instead of asking a network why it acted, the work tries to quantify how much of the model’s internal decision-relevant signals line up with the game objects a human would consider meaningful.
The starting point is the diversity hypothesis from an (at the time) unpublished OpenAI paper by Jacob Hilton and Chris Olah: interpretable features emerge at a given level of abstraction if and only if the training distribution is diverse enough at that level. “Diversity” is defined pragmatically as the amount of distinct training inputs—e.g., how many distinct levels an agent is trained on. In CoinRun, the agent’s environment varies across assets, textures, and platform layouts, so increasing the number of trained-on levels increases the variety of visual and positional patterns the model must learn.
Prior work tested the hypothesis using a human-in-the-loop process: researchers inspect attribution-based feature signals and manually decide whether each feature corresponds to something a person can recognize. The results show a clear trend: models trained on very few levels (around 100) have only about 1 out of 5 features that humans can interpret, while models trained on far more levels (around 100,000) rise to roughly 4 out of 5. Performance also improves with more training data, and interpretability appears to improve alongside it.
Orbay’s contribution is an attempt to replace the human loop with an algorithmic metric. The project uses attribution—computed via derivatives of the model output with respect to inputs—to produce saliency maps that indicate which pixels (or regions) most influence the model’s decisions. In CoinRun, attribution is applied not just to a whole network, but to parts tied to the agent’s control and to a value function (an estimate of how good a state is). The resulting saliency can be overlaid on the game frame to see whether the model focuses on meaningful objects (like enemies to avoid or platforms to use) or on irrelevant artifacts.
To quantify interpretability, Orbay defines a score based on the overlap between attribution and “objects of interest” masks: the numerator counts intersecting pixels where saliency lands on meaningful regions, and the denominator normalizes by total attribution area. Averaging this overlap across many frames and across many features yields an overall interpretability score.
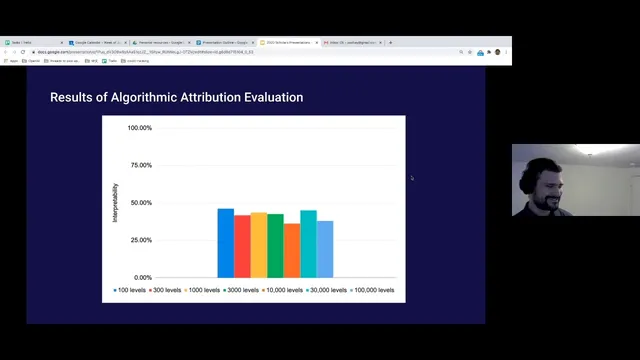
The metric initially fails to match the human-in-the-loop results: it lands around 35–40% rather than the expected higher interpretability for diverse training. The shortfall is traced to practical issues—attribution regions are often much larger than the small, localized examples used to illustrate the method, sometimes covering a large fraction of the screen. That makes overlap-based scoring less discriminative. A refinement using receptive fields and weighting connected versus less-connected network parts is mentioned as a partial fix, but the current definition still doesn’t work reliably.
Orbay’s conclusion is cautious but forward-looking: interpretability can likely be computed algorithmically, but the overlap-based definition needs refinement and validation beyond CoinRun and beyond the current experimental setup. The project also clarifies that good attribution/saliency alignment is treated as a proxy for interpretability—grounded in how humans attend to salient objects—rather than a strict causal guarantee.
Cornell Notes
The project tests a link between training diversity and interpretability in CoinRun, where models trained on more distinct levels tend to produce features humans can understand. Prior human-in-the-loop work found interpretability rises from about 1/5 interpretable features (≈100 levels) to about 4/5 (≈100,000 levels). Orbay tries to replace that slow human process with an algorithmic metric using attribution (saliency via derivatives) and an overlap score between attribution maps and “objects of interest” masks. The overlap metric underperforms, landing around 35–40% interpretability, largely because attribution regions are often too large and cover much of the screen. The takeaway is that algorithmic interpretability is feasible in principle, but the current definition needs refinement and broader testing.
What does “interpretability” mean in this project, and why does it matter for neural networks?
How does the diversity hypothesis connect training data to interpretable features?
What role does attribution (saliency) play in the attempt to quantify interpretability?
How is Orbay’s algorithmic interpretability score constructed?
Why did the overlap-based interpretability metric underperform compared with human judgments?
What do the Q&A comments imply about generalizing this approach beyond CoinRun?
Review Questions
- How does the project operationalize “diversity” and “level of abstraction” when testing the diversity hypothesis in CoinRun?
- Describe how attribution is computed conceptually and how it is used to generate saliency maps for the agent’s decisions.
- What specific failure mode caused the overlap-based interpretability score to land around 35–40%, and what refinement was proposed to address it?
Key Points
- 1
Interpretability is treated as a measurable proxy for how much a model’s decision-relevant signals align with human-recognizable objects, rather than as a purely qualitative judgment.
- 2
The diversity hypothesis predicts interpretable features emerge when training data is diverse enough at the relevant abstraction level; in CoinRun, diversity is approximated by the number of distinct levels trained on.
- 3
Human-in-the-loop attribution inspection previously showed interpretability rising from about 1/5 interpretable features (~100 levels) to about 4/5 (~100,000 levels).
- 4
Attribution-based saliency maps (via derivatives of outputs with respect to inputs) are used to identify which pixels the model attends to for both control and value estimation.
- 5
Orbay’s algorithmic metric computes interpretability as normalized overlap between attribution maps and masks of “objects of interest,” averaged across many frames and features.
- 6
The overlap metric underestimates interpretability (about 35–40%) because attribution regions are often too large, reducing the discriminative power of overlap.
- 7
Algorithmic interpretability appears feasible but requires refinement (e.g., receptive-field handling and weighting) and validation across domains beyond CoinRun.