Rotary Positional Embeddings (RoPE): Part 1
Based on West Coast Machine Learning's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
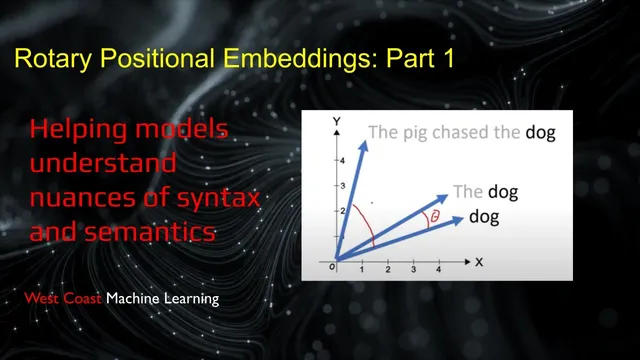
RoPE rotates query and key vectors by position, so attention scores depend directly on relative offsets (n − m) rather than requiring the model to infer relative distance from an additive absolute signal.
Briefing
Rotary Positional Embeddings (RoPE) replace the usual “add a position vector” approach with a rotation-based scheme that bakes relative distance directly into attention scores. Instead of shifting token embeddings by an absolute position signal, RoPE rotates query and key vectors in a complex-number-inspired way so that the dot product between a query at position m and a key at position n depends on the relative offset (n − m). That design aims to make relative positioning easier for Transformers to use—one reason RoPE has become a default choice in many modern architectures.
The session starts by revisiting the classic Transformer pipeline from “Attention Is All You Need.” Tokens get learned embeddings, then sinusoidal positional encodings are added additively to those embeddings. Those sinusoidal features use sine and cosine waves at multiple frequencies (scaled by terms involving 10,000 and dimension index), producing a unique high-dimensional signature for each absolute position. The discussion then drills into why this absolute, additive method can make relative attention harder: even though the model can, in principle, infer relative offsets from the combined signal, the mapping is not as straightforward as a direct relative-distance mechanism.
A key motivation emerges through comparisons to other positional strategies. T5-style relative position biases add a learned bias based on token offsets, but the overhead grows because shifting tokens requires recomputing the positional embedding/bias structure. The group contrasts this with RoPE’s promise: relative offsets should appear naturally inside the attention computation rather than being bolted on as an extra bias term.
RoPE’s core math is presented as a rotation applied to paired dimensions of the embedding vector. In 2D intuition, each token’s representation is rotated by an angle proportional to its position; in higher dimensions, the same idea is applied block-wise across many coordinate pairs. When query and key are rotated by their respective positions, the attention dot product simplifies so that it effectively becomes a function of the relative angle difference—meaning the attention score is invariant to absolute location and depends on distance between tokens. The session also addresses the “absolute vs relative” nuance: RoPE does encode absolute position information, but it’s not directly readable from the rotated embedding in the same way as additive sinusoidal encodings; extracting absolute position requires knowing the original token embedding.
Practical behavior gets attention too. Visualizations and experiments highlight that different embedding dimensions correspond to different frequency bands, producing a correlation structure that is strongest for nearby tokens and decays for far offsets, with periodic “wiggles” due to the sinusoidal nature of the rotations. The group notes that RoPE can be extended to longer contexts via position interpolation (resampling the underlying sinusoidal structure), typically with some short fine-tuning to adapt the model.
Finally, the discussion pivots to a related idea: “warp RoPE” (and a broader signal-processing framing). One participant proposes a warping approach inspired by bilinear transforms to map infinite frequency axes onto a finite unit circle, but flags drawbacks for recursive/online use. The alternative is a truncated infinite impulse response (TIR) style method that enforces a finite sliding-window memory by subtracting the tail of an infinite system—yielding a controllable, finite context length without quadratic attention cost. The takeaway is that RoPE’s rotation trick is both a relative-position mechanism and a stepping stone toward hybrid memory systems that can trade off context length, compute, and long-range tracking.
Cornell Notes
RoPE (Rotary Positional Embeddings) changes how Transformers use position by rotating query and key vectors instead of additively injecting position into token embeddings. The attention score between positions m and n becomes a function of the relative offset (n − m), because the dot product of rotated vectors simplifies to depend on the relative rotation angle. This targets a weakness of additive sinusoidal encodings, where relative positioning is harder to learn even though absolute position signatures exist. RoPE also yields a frequency-mixed correlation pattern: nearby tokens correlate more strongly, while far offsets show decay and periodic oscillations. RoPE can extend to longer contexts via position interpolation, and the discussion connects these ideas to signal-processing-inspired “warp” and truncated-memory variants for efficient long-range behavior.
How does RoPE differ from the original Transformer’s sinusoidal positional encoding?
Why is relative positioning considered easier with RoPE than with additive sinusoidal encodings?
What does the “frequency band” intuition mean for RoPE’s behavior across distance?
What is the “absolute vs relative” nuance people often miss with RoPE?
How does RoPE support longer context windows beyond the training length?
What is “warp RoPE” / the signal-processing angle, and what alternative is proposed?
Review Questions
- In RoPE, why does the attention score between positions m and n become a function of (n − m)? Identify the role of rotating query and key vectors.
- Compare additive sinusoidal positional encoding and RoPE in terms of how relative positioning information is made available to the Transformer.
- What causes RoPE’s correlation to decay with distance while still showing periodic oscillations? Relate this to frequency components.
Key Points
- 1
RoPE rotates query and key vectors by position, so attention scores depend directly on relative offsets (n − m) rather than requiring the model to infer relative distance from an additive absolute signal.
- 2
The original Transformer’s sinusoidal positional encoding adds sine/cosine vectors to token embeddings; it provides absolute position signatures but makes relative positioning less direct to learn.
- 3
RoPE’s rotation is implemented by pairing embedding dimensions and applying block-wise 2D rotations; the dot product algebra collapses to a relative-angle function.
- 4
RoPE’s multi-frequency design yields stronger similarity for nearby tokens and decaying, oscillatory correlation for far offsets due to periodic rotations.
- 5
RoPE can extend to longer contexts using position interpolation (resampling the positional structure), often with some fine-tuning to adapt attention behavior.
- 6
Relative-position bias methods (e.g., T5-style) can add offset-dependent terms but may introduce overhead because positional/bias structures must be recomputed as tokens shift.
- 7
A signal-processing framing motivates “warp” and truncated-memory variants that aim to control context length efficiently, potentially combining finite RoPE-like behavior with longer-decay memory modules.