Self Attention Geometric Intuition | How to Visualize Self Attention | CampusX
Based on CampusX's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Self-attention turns token embeddings into context-aware representations by computing similarity weights between tokens and then taking a weighted sum of value vectors.
Briefing
Self-attention in Transformers can be visualized as a geometry-driven “pull” between word embeddings: each token’s new representation is a weighted combination of other tokens, where the weights come from similarity scores computed via dot products. That geometric intuition matters because it turns a dense block of matrix math into something you can picture—angles between vectors determine which words influence each other, and the softmax turns those similarities into attention weights.
The walkthrough starts with a quick recap of the standard self-attention pipeline on a two-word example like “money bank.” First, each word gets an embedding vector (e.g., e_money and e_bank). Then three learned projection matrices—W_Q, W_K, and W_V—transform these embeddings into query, key, and value vectors. For each word, the model computes similarity scores by taking dot products between queries and keys (Q·K), scales them by 1/√d_k to control magnitude, and applies softmax to convert scores into normalized weights. Finally, each token’s output vector is formed as a weighted sum of value vectors (the V vectors), using those attention weights.
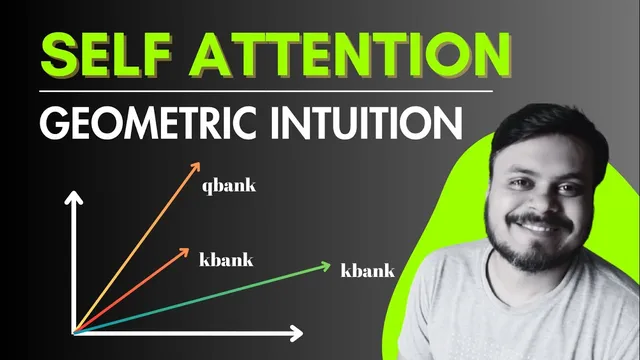
The core addition in this session is the geometric lens. Embeddings are treated as vectors in a space (the transcript uses a simplified 2D visualization for intuition, even though real embeddings are high-dimensional). The projection step is described as a linear transformation: dotting a vector with a matrix “moves” it into new vector directions, producing Q, K, and V. Next, similarity becomes geometry: the dot product is tied to the angle between vectors—smaller angular distance yields a larger dot product, which yields larger attention after scaling and softmax.
Using the “money bank” pair, the intuition is that the “bank” token’s output vector (y_bank) shifts toward the “money” token’s embedding direction after attention is applied. In the transcript’s comparison, the original bank embedding sits farther away, but the self-attended bank representation ends up much closer to money. That’s framed as gravity-like behavior: the context word “money” pulls “bank” into a context-appropriate meaning.
The explanation extends this idea to counterfactual context. If the surrounding word were “river” instead of “money,” the model would pull “bank” toward the “river” context, producing a different contextual representation. The mechanism is described as context-aware because attention weights depend on the current sentence’s token relationships—learned patterns from the dataset decide which words should influence each other.
To make the geometry feel tangible, the transcript also references embedding visualizations using dimensionality reduction (PCA) to project high-dimensional word vectors into 2D/3D plots. In those plots, semantically related words cluster together, reinforcing the idea that embeddings encode meaning as spatial relationships. Overall, the takeaway is that self-attention is not just computation—it’s a context-driven re-composition of token meaning based on vector similarity and weighted aggregation.
Cornell Notes
Self-attention can be understood geometrically: word embeddings are vectors, and attention weights come from how closely aligned (angled) query and key vectors are. Dot products measure similarity, scaling by 1/√d_k stabilizes the scores, and softmax converts them into weights. Each token’s new representation is then a weighted sum of value vectors, so the output moves toward the most relevant context tokens. In the “money bank” example, the “bank” representation shifts closer to “money,” illustrating context-aware meaning; swapping “money” for “river” would shift “bank” toward “river” instead.
How does the transcript connect dot products to geometry in self-attention?
What role does scaling by 1/√d_k play in the attention computation?
Why does the transcript say self-attention “pulls” one word embedding toward another?
How does the example show context dependence using “money bank” versus “river bank”?
What does the transcript claim about dimensionality reduction (PCA) and embedding meaning?
How does the projection step (Q, K, V) fit into the geometric story?
Review Questions
- In the transcript’s geometric intuition, what determines whether one token strongly influences another token’s output representation?
- Why does the transcript emphasize both scaling (1/√d_k) and softmax in turning dot-product similarities into attention weights?
- Using the “bank” example, describe what would need to change for the output representation to shift toward “river” instead of “money” (in terms of similarity and weights).
Key Points
- 1
Self-attention turns token embeddings into context-aware representations by computing similarity weights between tokens and then taking a weighted sum of value vectors.
- 2
Dot products act as a geometric similarity measure: smaller angles between vectors produce larger dot products and therefore larger attention weights after softmax.
- 3
Scaling by 1/√d_k helps control dot-product magnitude so softmax produces stable, meaningful attention distributions.
- 4
The output embedding for an ambiguous word (like “bank”) shifts toward the embedding direction of the most relevant context word (like “money”).
- 5
Changing the surrounding context word (e.g., replacing “money” with “river”) changes similarity scores, which changes attention weights and therefore changes the contextual meaning representation.
- 6
Dimensionality reduction (such as PCA) is used to visualize high-dimensional embeddings, where semantically related words tend to cluster in the projected space.