Software Engineering (2) - Infrastructure and Tooling - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Python’s popularity in deep learning is driven primarily by its mature libraries such as NumPy, pandas, TensorFlow, and PyTorch.
Briefing
Python has become the default language for full-stack deep learning less because it’s inherently perfect for scientific computing and more because its ecosystem is unmatched: NumPy, pandas, TensorFlow, and PyTorch supply the core building blocks people rely on. That practical reality matters because it shifts the software-engineering question from “Which language is best?” to “Which tooling and guardrails make that language reliable at scale?” The transcript also flags Python’s weaknesses for scientific work—like the lack of static typing—and points to mitigations such as type hints, editor support, and automated checks.
Tooling choices strongly shape how code gets written and maintained. For data science, notebooks (often in Jupyter) remain a fast way to explore data and prototype quickly, but they come with tradeoffs: version control is messy because notebooks mix input code with output results; rerendering can churn images and make diffs noisy; and testing is hard because execution order can drift, producing results that are difficult to verify. The transcript argues that notebooks are best treated as a first draft—useful for early iteration—but not as the long-term foundation for reproducible, testable systems.
As teams move from solo experimentation to collaboration, the emphasis shifts to code style and static analysis. Codifying style rules into automated checks helps catch errors early, including issues that Python would otherwise only reveal at runtime—such as calling a function with the wrong number of arguments. Static type checking adds another layer: Python 3.5 introduced type hints, and modern editors can surface mismatches immediately. The example given is a training function where parameters like batch size or GPU indices are expected to be integers; passing a float (e.g., 12.1) can be flagged while writing code rather than after execution.
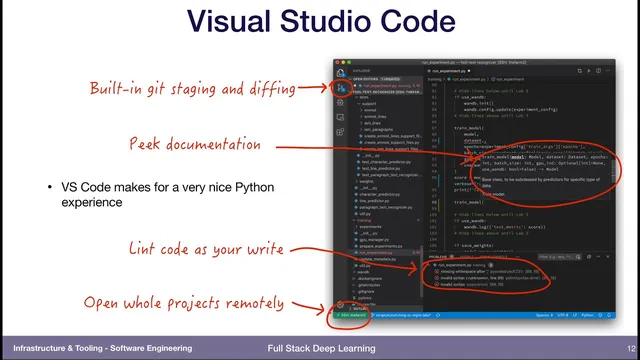
Editor workflow is presented as a practical lever for quality. Vim and Emacs are described as classic tools, but data science workflows typically center on Jupyter. Visual Studio Code is recommended as a bridge: it offers a smoother Python experience than notebooks alone, including built-in version control features, documentation popups while typing, and—crucially—remote development so projects can be opened locally while running on machines with the needed GPUs. For deeper Python work, PyCharm is positioned as a full integrated development environment.
Finally, the transcript addresses how to share interactive model demos without turning them into unmaintainable web apps. Streamlit is highlighted as a lightweight packaging layer for data-science artifacts: functions can be decorated to add UI controls like sliders, and smart caching avoids rerunning expensive steps when only non-data code changes. The goal is a simple workflow—generate an applet, get a URL, and share it—so teammates can interact with trained models without building and maintaining a Flask/JavaScript stack.
Across these points, the throughline is infrastructure discipline: use notebooks for exploration, then migrate toward editor-backed development, automated linting/type checking, conventional testing practices, and shareable interfaces that don’t collapse under maintenance cost.
Cornell Notes
Python’s dominance in deep learning is attributed to its libraries—NumPy, pandas, TensorFlow, and PyTorch—more than to language features alone. Because Python is dynamically typed, teams rely on tooling: static analysis and type hints (introduced in Python 3.5) help catch mistakes like wrong argument types before running code. Jupyter notebooks speed early experimentation but create problems for version control, testing, and reproducibility due to mixed inputs/outputs and out-of-order execution. Visual Studio Code is recommended as a practical step up from notebooks, especially with remote development for GPU access. For sharing interactive results, Streamlit provides a simpler alternative to building full web apps, using decorators and caching to keep updates fast.
Why does Python win for deep learning even though it has drawbacks for scientific computing?
What makes Jupyter notebooks difficult to manage in a team setting?
How do static analysis and type hints reduce bugs in Python workflows?
What workflow improvements does Visual Studio Code offer compared with notebook-first development?
How does Streamlit change the way interactive model demos get shared?
Review Questions
- What specific problems with notebooks make reproducibility and testing harder, and how do out-of-order execution artifacts contribute?
- How do type hints (introduced in Python 3.5) and static type checking prevent runtime errors like passing the wrong type to a training function?
- Why is remote development in Visual Studio Code particularly valuable for deep learning work on GPU machines?
Key Points
- 1
Python’s popularity in deep learning is driven primarily by its mature libraries such as NumPy, pandas, TensorFlow, and PyTorch.
- 2
Editor and workflow choices can determine whether code stays maintainable, especially when moving from solo notebooks to team development.
- 3
Static analysis and linting catch certain bugs immediately—like incorrect function calls—before code is executed.
- 4
Type hints in Python 3.5 enable static type checking that can flag type mismatches (e.g., float passed where an integer is expected) while writing code.
- 5
Jupyter notebooks are best treated as a first draft because version control, testing, and reproducibility suffer from mixed inputs/outputs and execution-order issues.
- 6
Visual Studio Code is recommended as a practical upgrade from notebook-only work, with built-in Python support and remote project access for GPU usage.
- 7
Streamlit offers a low-maintenance way to package interactive data-science results, using decorators and caching instead of building full web apps.