Start Simple (2) - Troubleshooting - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
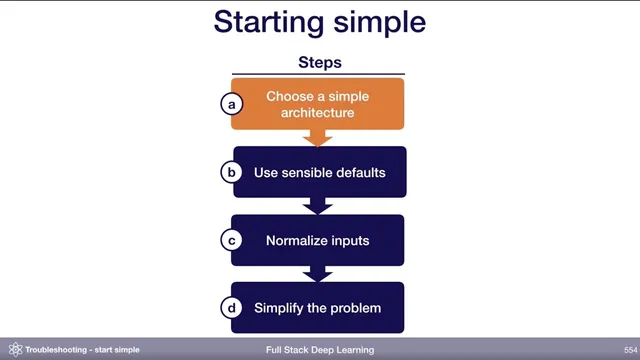
Choose a baseline architecture based on data modality (images → LeNet-style CNN; sequences → LSTM or temporal/causal convolutions; other cases → simple fully connected network).
Briefing
Starting simple is the fastest way to find out whether poor model performance comes from a hard problem or from avoidable bugs in the pipeline. The core move is to begin with an architecture that matches the shape of the data—then lock in sensible hyperparameter defaults, normalize inputs, and only then scale up complexity. This approach matters because deep learning failures often look identical from the outside: low accuracy could mean the task is inherently difficult, or it could mean data handling, preprocessing, or training settings are broken.
Architecture choice should start with the data modality, not with chasing the latest state-of-the-art paper. If the inputs look like images, a LeNet-style convolutional network is a practical first baseline. If the inputs are sequences, the classic starting point is an LSTM, though temporal or causal convolutions can be a more sensible modern alternative. As the problem matures, teams can move toward attention-based models or WaveNet-like architectures. For anything that doesn’t fit neatly, a fully connected neural network with one hidden layer is suggested as a fallback baseline. The point isn’t that these models are optimal; it’s that they’re simple enough to implement and debug, making it easier to establish a baseline before attempting more sophisticated systems.
Real-world datasets often combine multiple modalities, so the recommended strategy is to encode each modality separately into a lower-dimensional representation. Images can go through a CNN, sequences through an LSTM, and then each branch’s output is flattened into a single vector per input. Those vectors are concatenated and passed through fully connected layers to produce the final output. This “not state-of-the-art, but easy to try” design is meant to get a working end-to-end system quickly.
Hyperparameters should also begin with defaults that reduce the chance of silent failure. The guidance favors the Adam optimizer with a learning rate of 3e-4. For fully connected or convolutional models, the starting point for activations is 10H, along with recommended weight initialization schemes. Regularization and data normalization layers (like batch norm, layer norm, or weight norm) are intentionally deferred at first: they can be crucial for peak performance later, but they also introduce many opportunities for bugs. The workflow is to debug everything else first, then add normalization once the baseline is stable.
Input normalization is still treated as essential early on: subtract the mean and divide by the variance. For images, scaling values to ranges like 0–1 or -0.5 to 0.5 is acceptable. Finally, simplifying the problem itself—using a smaller dataset, fewer classes, smaller images, or even a synthetic training set—improves iteration speed and clarifies whether the implementation is the bottleneck. The pedestrian detection example illustrates the workflow: start with a subset of about 10,000 images, use a LeNet-style architecture, sigmoid cross-entropy loss, Adam, and no regularization. If performance is still poor, the team can then decide whether to increase model complexity, add fine-tuning later, or revisit the pipeline—one change at a time so causes are easier to isolate.
Cornell Notes
The troubleshooting approach emphasizes building a baseline that is simple enough to debug quickly. Start by matching architecture to data type: LeNet-style CNNs for images, LSTM (or temporal/causal convolutions) for sequences, and fully connected networks with one hidden layer for other cases. For multiple modalities, encode each input separately (CNN/LSTM), flatten to vectors, concatenate, and finish with fully connected layers. Use sensible training defaults like Adam with a learning rate of 3e-4, normalize inputs by mean/variance, and initially avoid regularization/normalization layers that can add bugs. Also shrink the task early—fewer images/classes or smaller synthetic data—to increase iteration speed and determine whether failures come from the task or the implementation.
How should teams decide when to switch from a simple model to a more complex one?
Why recommend deferring normalization layers like batch norm or layer norm at first, even though they can improve final performance?
What is the recommended approach for combining multiple input modalities in one model?
What training defaults are suggested for an initial baseline?
Why simplify the dataset and task early on?
Review Questions
- What specific criteria should guide the choice of a baseline architecture for images vs sequences?
- Why is input normalization (mean/variance scaling) treated differently from adding normalization layers like batch norm or layer norm?
- In a multi-modal setup, what is the step-by-step method for turning each modality into a vector and combining them?
Key Points
- 1
Choose a baseline architecture based on data modality (images → LeNet-style CNN; sequences → LSTM or temporal/causal convolutions; other cases → simple fully connected network).
- 2
For multiple modalities, encode each input type separately, flatten to vectors, concatenate, and then use fully connected layers for the final output.
- 3
Use sensible training defaults early: Adam with a learning rate of 3e-4 and recommended activation/weight initialization settings.
- 4
Normalize inputs by subtracting the mean and dividing by the variance; scaling image values to ranges like 0–1 or -0.5 to 0.5 is acceptable.
- 5
Avoid regularization and normalization layers at the very start because they can introduce many bugs; add them only after the pipeline is stable.
- 6
Simplify the task early (smaller dataset, fewer classes, smaller images, or synthetic data) to increase iteration speed and diagnose whether the bottleneck is the task or the implementation.
- 7
Start without fine-tuning; add fine-tuning only after training-from-scratch on a small dataset shows clear limits.