The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Based on AI Researcher's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
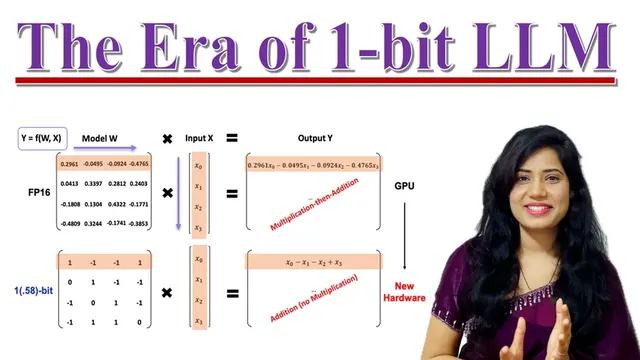
BitNet B1.58 quantizes Transformer weights to ternary values (-1, 0, +1), enabling inference to avoid multiplication-heavy computation.
Briefing
Large language models built with ultra-low-precision weights—specifically BitNet B1.58, which uses only three weight values (-1, 0, +1)—are showing a path to faster, cheaper, and more energy-efficient inference without giving up much language quality. The core shift is replacing 16-bit floating-point math with ternary arithmetic, so the model can avoid expensive multiplications during inference. That matters because today’s LLM deployments are often constrained less by model quality than by latency, memory footprint, and power draw—limits that make on-device and large-scale serving costly.
Traditional LLMs such as GPT-style Transformer models typically rely on 16-bit floating-point operations. Those higher-precision computations help accuracy, but they inflate model size, increase memory bandwidth demands, and add energy cost—leading to higher latency and making deployment on smartphones and other constrained hardware harder. One common strategy to reduce cost is shrinking parameter counts, but that can reduce capability. Another is lowering precision, but many approaches still keep multiplications and wider numeric ranges.
BitNet B1.58 takes a different route: it treats weights as ternary values rather than a wide set of decimals. The architecture keeps the familiar Transformer components—attention mechanisms and feed-forward networks—but changes how linear layers compute. In the ternary setup, weights are mapped to -1, 0, or +1. During inference, the model replaces multiplication-heavy operations with simpler addition/subtraction logic: multiplying by +1 becomes addition, multiplying by -1 becomes subtraction, and multiplying by 0 effectively drops the input contribution. This turns the core math into operations that are faster and cheaper on hardware, while also reducing the memory needed to store weights.
The reported benefits cluster into three practical areas. First is reduced latency: simpler arithmetic shortens the time to produce outputs. Second is lower memory usage: storing ternary weights requires less space than storing 16-bit floating-point weights. Third is reduced energy consumption: arithmetic operations become less costly, enabling more efficient throughput.
Across comparisons with a 16-bit precision LLaMA-style baseline, BitNet B1.58 maintains similar perplexity (a measure of language modeling uncertainty) while using significantly less memory and achieving better latency. Scaling results are presented as well: even at larger model sizes (including a highlighted 3B configuration), the efficiency gains persist. On zero-shot tasks—where models are evaluated on NLP benchmarks without task-specific training—BitNet B1.58 is reported to outperform LLaMA on many individual tasks, with overall average zero-shot accuracy tending to rise as models scale.
Serving efficiency is reinforced by throughput and batching metrics. Graphs indicate BitNet’s decoding latency stays consistently lower than the baseline across model sizes, with speedups reported as factors (e.g., 1.67x, 2.71x). Memory consumption is reduced by multiple factors as well (e.g., 2.93x, 3.55x). In a direct comparison at 70B parameters, BitNet supports much larger maximum batch sizes and achieves substantially higher throughput (reported near 9x).
Energy analysis breaks down arithmetic costs and attributes large savings to the move away from floating-point multiplication. Reported reductions in arithmetic energy reach roughly 7.14x for the operation breakdown, with overall energy efficiency improvements growing at larger model sizes (examples include 18.6x and 29.1x). On standard language understanding benchmarks, the 3B BitNet B1.58 model is described as competitive with StableLM-3B, with slightly higher average accuracy.
Taken together, BitNet B1.58 reframes the “1-bit era” as a spectrum: it’s not purely binary, but a ternary system whose effective complexity corresponds to about 1.58 bits (via log2(3)). The implication is clear—future LLM scaling may depend as much on hardware-friendly numeric formats as on parameter counts, enabling high-quality language models that are cheaper to run and easier to deploy.
Cornell Notes
BitNet B1.58 replaces 16-bit floating-point weights with ternary weights (-1, 0, +1), enabling inference to rely on addition/subtraction instead of multiplication. The approach keeps Transformer attention and feed-forward structure, but changes linear-layer math so multiplying by +1 becomes add, by -1 becomes subtract, and by 0 ignores the input. Reported results show significantly lower memory use and consistently lower decoding latency than a 16-bit LLaMA-style baseline, while keeping perplexity similar. On zero-shot NLP tasks, BitNet B1.58 is reported to match or outperform LLaMA across many benchmarks, with average accuracy improving as model size increases. Energy breakdowns attribute large savings to avoiding floating-point multiplication, with efficiency gains that grow at larger scales.
Why does switching from 16-bit floating-point weights to ternary weights (-1, 0, +1) reduce inference cost?
What does “1.58 bits” mean if the model uses three states?
How do perplexity and latency trade off in the reported comparisons?
What is zero-shot accuracy, and what pattern is reported as models scale?
How do throughput and batch size relate to real-world deployment?
Where do the energy savings come from, according to the arithmetic breakdown?
Review Questions
- If weights are restricted to -1, 0, +1, what exact arithmetic replacements occur during inference for each weight value?
- How does the transcript connect log2(3) to the “1.58 bits” label, and why is that label still relevant to a ternary model?
- Which metrics in the transcript are used to represent (a) language quality and (b) serving efficiency, and what direction of change is reported for BitNet versus the 16-bit baseline?
Key Points
- 1
BitNet B1.58 quantizes Transformer weights to ternary values (-1, 0, +1), enabling inference to avoid multiplication-heavy computation.
- 2
Multiplying by +1 becomes addition, multiplying by -1 becomes subtraction, and multiplying by 0 drops the contribution—simplifying linear-layer math.
- 3
Reported comparisons show similar perplexity to a 16-bit precision LLaMA baseline while delivering lower latency and substantially reduced memory usage.
- 4
Zero-shot evaluations report BitNet B1.58 outperforming LLaMA on many tasks at highlighted model sizes, with average accuracy tending to improve as models scale.
- 5
Decoding latency, throughput, and maximum batch size improve for BitNet, supporting more efficient real-world serving.
- 6
Energy savings are attributed to replacing floating-point multiplication with cheaper integer arithmetic, with larger efficiency gains at bigger model sizes.
- 7
The “1.58 bits” framing reflects the effective information content of a three-state system (log2(3) ≈ 1.58), not a strict two-state binary model.