The line of code that took down the Internet
Based on The PrimeTime's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Cloudflare’s reverse-proxy position means many services depend on it as an intermediary; when it fails, traffic can’t pass through the filtering and routing layer.
Briefing
Cloudflare’s outage is traced to a cascading failure triggered by an unexpected surge in “feature flags” delivered to its bot-management system—so large that the service’s performance safeguards treated it as a blow-up condition and crashed. The key mechanism is Cloudflare’s reverse-proxy architecture: most internet traffic passes through Cloudflare, where requests are filtered (including bot checks and rule enforcement), then served from cache when possible, or forwarded to the origin server when not. When Cloudflare fails, the “middle bar” disappears, taking down sites and services that rely on it—explaining why platforms like Twitter and monitoring sites such as downdetector went offline when Cloudflare went down.
At the center of the incident is Cloudflare Bot Management, which uses roughly 60 behavioral features to build a statistical model that classifies traffic as bot or non-bot, and as high-risk or low-risk. Those features must refresh frequently—about every five minutes—so the system can adapt as attacks evolve without requiring engineers to redeploy code for every change. Cloudflare can also update bot-management behavior quickly when new threats appear, allowing websites to stabilize within minutes.
The failure began when Cloudflare also changed how it retrieves data from a storage service. When the updated “feature flags” arrived, the bot-management component received more than expected: instead of about 60 features, it received more than 200. That difference mattered because Cloudflare uses performance-oriented “pre-allocation,” setting memory and other resources at startup to keep latency steady—an approach likened to NASA’s rule of designing safety-critical systems so the operating environment doesn’t force unpredictable reallocations or timing shifts. In this design, receiving more than 200 features violates an internal assumption; the system treats it as an unrecoverable condition and crashes rather than degrading unpredictably.
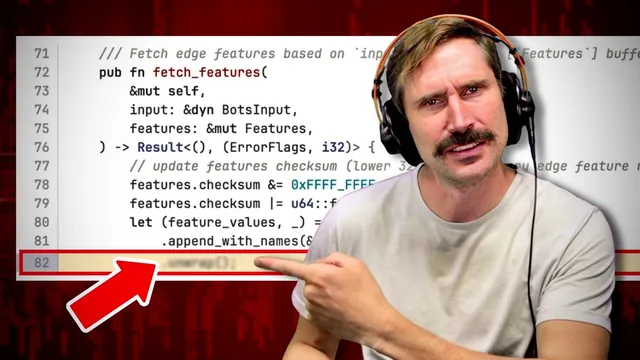
The transcript emphasizes that the crash wasn’t about Rust being inherently bad. The discussion notes that Rust’s common “unwrap/expect” patterns act like assertions: if they fail, they panic and terminate the program. In server software, that kind of termination can translate directly into dropped requests and cascading outages, so relying on unwrap-like behavior in a server context is risky. Still, the argument concludes that the underlying constraint—unexpected feature-flag volume—would likely have produced a similar failure in other languages as well.
Finally, the takeaway is less about blaming a programming language and more about engineering tradeoffs: fast, stable performance often depends on strict invariants, and when configuration or data retrieval changes violate those invariants, the result can be abrupt system failure. The incident becomes a case study in how small integration mismatches—like “plus 200” flags instead of “about 60”—can trigger large-scale downtime when safeguards are designed for predictable inputs.
Cornell Notes
Cloudflare’s outage is linked to bot-management receiving far more feature flags than expected. Bot Management normally uses about 60 features, refreshed roughly every five minutes, to classify traffic as bot or non-bot. After a related change to how data is retrieved from storage, the system received 200+ feature flags instead of ~60, violating an internal performance assumption tied to memory pre-allocation. With those invariants broken, the service crashed, and because Cloudflare sits in the reverse-proxy path for much of the internet, the failure cascaded to many sites. The discussion also warns that Rust’s unwrap/expect panics can turn unexpected conditions into full server termination, though the root issue is framed as the violated constraint rather than Rust itself.
Why does a Cloudflare failure take down so many unrelated websites?
What is Cloudflare Bot Management, and how does it decide whether traffic is a bot?
How did the incident start according to the transcript’s explanation?
Why is “200+ feature flags” described as dangerous rather than merely “more data”?
What role do Rust unwrap/expect panics play in the failure narrative?
Does the transcript blame Rust itself?
Review Questions
- What architectural role does a reverse proxy play in why Cloudflare outages propagate to many services?
- How do pre-allocation and strict invariants turn an unexpected configuration change into a crash rather than a degraded performance state?
- Why are unwrap/expect patterns considered especially risky in long-running server processes?
Key Points
- 1
Cloudflare’s reverse-proxy position means many services depend on it as an intermediary; when it fails, traffic can’t pass through the filtering and routing layer.
- 2
Bot Management relies on a frequently refreshed set of roughly 60 features to classify traffic as bot/non-bot and high/low risk.
- 3
A storage-related change coincided with bot-management updates, causing the system to receive 200+ feature flags instead of the expected ~60.
- 4
Cloudflare’s performance design uses pre-allocation based on expected inputs; receiving out-of-spec feature counts violates invariants and triggers a crash.
- 5
unwrap/expect in Rust behave like assertions; when they fail they panic, which can turn unexpected conditions into full server termination.
- 6
The incident is framed as an integration/constraint failure more than a condemnation of Rust as a language choice.