Thematic analysis with ChatGPT | PART 2- Coding qualitative data with ChatGPT
Based on Qualitative Researcher Dr Kriukow's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
After initial coding, reorganize codes into groups before attempting final themes, using both manual judgment and ChatGPT-assisted sorting.
Briefing
Qualitative thematic analysis with ChatGPT doesn’t replace the core work of coding—it mainly accelerates the messy middle: reorganizing a large list of initial codes into workable groups. After generating initial codes with ChatGPT, the next step is to sort those codes into meaningful clusters (not yet final themes), then tighten the categories so they align with the study’s research questions—especially when the analysis includes both positive and negative influences on outcomes like job satisfaction.
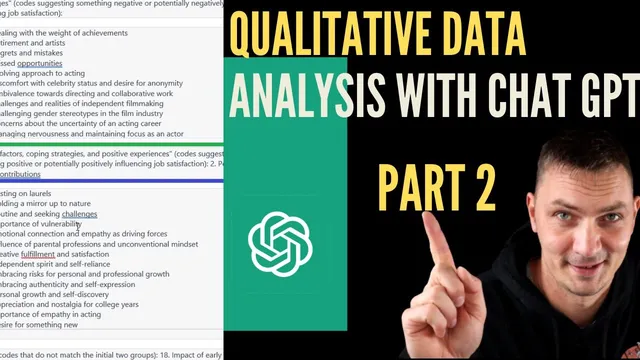
The workflow starts with a practical audit of the coded material. Codes are color-coded so researchers can trace each code back to the interview it came from. Just as important, quotes must remain attached to codes; without the original quotations, later theme-building becomes hollow because there’s no evidence to support claims. The transcript emphasizes using search tools (e.g., Microsoft Word “Find”) to locate the quotes for any given code name, since ChatGPT reorganization will require repeatedly checking that the right evidence is still connected to the right label.
Before reorganizing, researchers also need to ensure the code list is complete and faithful to the data. If ChatGPT missed a relevant angle—such as a code that captures a limitation or challenge—researchers should add it manually. The guidance is blunt: too many codes are preferable to too few, because ChatGPT can only classify what it sees. This stage also involves scanning code summaries and deciding whether they fit the intended direction of the analysis (for example, the transcript’s focus includes both positive and negative factors affecting job satisfaction).
For grouping, the transcript recommends a hybrid approach: do some manual organization, but use ChatGPT to speed up first-pass sorting. A sample prompt assigns every code to one of three buckets: “challenges” (codes implying negative effects on job satisfaction), “positive factors” (codes implying positive effects), or “other” (codes that don’t clearly fit either). ChatGPT can be fast, but accuracy still needs human correction. The transcript shows this with misplacements—like a code that relates to “desire for something new” being incorrectly treated as a challenge—requiring researchers to move codes to the right group after checking the associated quotes.
Once codes sit in the right buckets, the next refinement is “clean-up” within each group: fix category errors, keep wording consistent, and only merge or rename codes carefully. Renaming creates a traceability problem—if a code label disappears, the researcher may lose the ability to find its quotes later. The workaround is to preserve the old wording in a comment or note before combining codes, so the evidence remains retrievable.
Finally, the transcript describes optional sub-grouping to support later theme development. For example, positive factors can be split into “personal” versus “external/workplace” influences, using additional ChatGPT prompts as brainstorming aids. The overall message is iterative and flexible: ChatGPT helps propose structure, but researchers must verify fit against the quotes, correct misclassifications, and maintain audit trails so themes can be defended with evidence.
Cornell Notes
After generating initial codes with ChatGPT, the next stage is to reorganize those codes into meaningful groups before forming final themes. Researchers must keep quotes traceable to codes—color-coding and using search tools (like Word’s Find) help locate the exact quotations later. ChatGPT can quickly assign each code to broad buckets such as “challenges,” “positive factors,” and “other,” but misclassifications are expected and must be corrected by checking the associated quotes. Researchers then clean up within groups, fix wording carefully, and merge codes only with a record of prior labels so evidence remains findable. Optional sub-grouping (e.g., personal vs external influences) can further prepare the path to final themes tied to research questions.
Why does quote traceability matter during code grouping, and how is it maintained?
What are the three broad groups used to organize codes in the example workflow?
What kinds of errors should researchers expect from ChatGPT during grouping?
How should researchers handle renaming or merging codes without breaking the evidence trail?
Why is adding additional codes sometimes necessary even when ChatGPT generated an initial list?
How can sub-grouping (like personal vs external factors) support later theme development?
Review Questions
- How would you verify that every grouped code still has an associated quote you can retrieve later?
- What steps would you take if ChatGPT places a clearly positive code into the “challenges” bucket?
- What record-keeping practice would you use before merging two codes with different labels?
Key Points
- 1
After initial coding, reorganize codes into groups before attempting final themes, using both manual judgment and ChatGPT-assisted sorting.
- 2
Keep quotes traceable to codes at every step; use color-coding and search tools to find quotations by code name.
- 3
Add missing codes when the data suggests additional positive/negative angles; too few codes can limit later theme quality.
- 4
Expect and correct ChatGPT misclassifications by checking the actual quotes tied to each code.
- 5
Maintain consistent wording when possible; if merging or renaming, record the old label so quotes remain findable.
- 6
Use broad buckets (challenges, positive factors, other) as a first-pass structure, then refine with sub-grouping aligned to research questions.
- 7
Treat sub-grouping prompts (e.g., personal vs external) as iterative brainstorming that must be validated against the quotations.