Towards Epileptic Seizure Prediction with Deep Network | Kata Slama | OpenAI Scholars Demo Day 2020
Based on OpenAI's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Seizure prediction is framed as a classification problem using pre-seizure neural signals converted into spectrograms.
Briefing
Epileptic seizure prediction is moving from a theoretical possibility toward a measurable machine-learning task: a deep network trained on intracranial voltage recordings can distinguish “safe” brain activity from patterns occurring up to an hour before an upcoming seizure. The practical significance is straightforward—better prediction could reduce injuries, anxiety, and quality-of-life barriers for people with epilepsy, and it may also support safer driving and closed-loop brain stimulation approaches.
Seizures happen when neurons fire in synchrony, sometimes spreading across the brain and causing loss of consciousness. Epilepsy affects about 1% of people worldwide, with disproportionate impact in developing countries. Because seizures are unpredictable, sufferers face physical risks from accidents and often lose the ability to drive. For many regions, that unpredictability also fuels anxiety and limits treatment options. Earlier work left open whether any reliable pre-seizure signal exists; more recent evidence suggests there is a detectable brain signature before seizures, even if clinicians can’t yet agree on what that signature looks like.
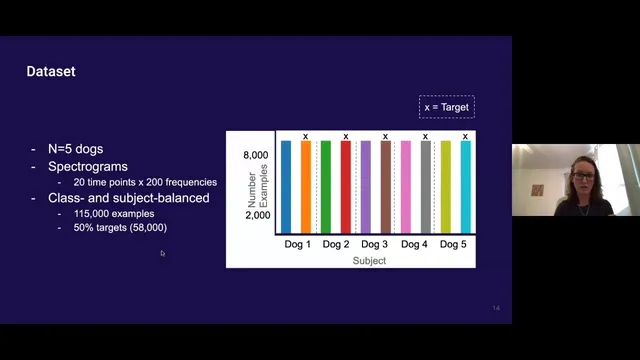
The project uses publicly available data from Cargill’s canine recordings: voltage sensor time series from multiple brain locations in five dogs. Each recording is segmented into epochs spanning from well before seizures (at least four hours) and from up to one hour before seizure onset. The pipeline converts these time windows into spectrograms—image-like representations that expose frequency content over time—then frames the task as classification between “danger” epochs (leading to a seizure) and “safe” epochs.
A key challenge is imbalance: one dog contributes most of the data, and there are far fewer danger epochs than safe epochs. Without correction, models can “cheat” by overfitting to the dominant dog or by defaulting to the majority class. The work addresses this by subsampling to balance both dogs and class labels. With this balanced setup, chance-level performance sits around 55%. A ResNet-18 model reaches about 69% accuracy, while a logistic regression baseline with standard preprocessing lands near chance.
Model quality is then evaluated through trade-off metrics rather than accuracy alone. An ROC curve area around 0.77 indicates moderate separability: aiming to capture 99% of seizures would still label only about 80% of safe epochs as safe, implying a substantial false-alarm burden. Precision-recall analysis paints a similar picture: targeting 99% seizure recall yields roughly 55% precision, meaning many “danger” predictions would not correspond to true seizures. A confusion matrix shows about 72% of true seizures correctly flagged, with remaining seizures missed.
The results are framed as promising but incomplete. Future improvements include hyperparameter tuning, stronger regularization, trying alternative architectures such as larger ResNets or sequence models, and revisiting preprocessing. There’s also a plan to interpret what the network learns using OpenAI’s interpretability tooling (including weight visualization and activation maximization). Practical questions raised in Q&A focus on data availability for patients: the training data excludes seizure-time recordings and relies on pre-seizure windows, and real-world deployment may require adapting models from intracranial signals to less invasive scalp EEG. The work also notes that seizure predictability may vary by seizure type and by how far in advance warning signals actually exist, motivating multi-label and hierarchical approaches (e.g., separate models for 10-minute versus 1-hour horizons) and longer temporal segments. Finally, it highlights an architectural opportunity: treating electrode channels as correlated rather than independent observations.
Cornell Notes
A deep learning model can classify intracranial voltage patterns as “safe” or “danger” based on spectrograms derived from time windows up to one hour before seizure onset. Using publicly available canine data, the project balances both class labels and dog identity to prevent the network from overfitting to the dominant subject or the majority class. A ResNet-18 trained from scratch reaches about 69% accuracy on the balanced dataset, with ROC-AUC around 0.77. Trade-off metrics show the cost of high recall: capturing 99% of seizures would still produce many false alarms (precision around 55% in the precision-recall view). Future work targets better accuracy via tuning, alternative architectures, interpretability, and more realistic prediction horizons and electrode correlation modeling.
Why is seizure prediction considered possible at all, given that clinicians can’t agree on a specific pre-seizure “signature”?
How does the project turn raw neural time series into something a vision model can learn from?
What data imbalance problems can break seizure prediction models, and how were they handled here?
What do ROC-AUC, precision-recall, and the confusion matrix reveal that accuracy alone can hide?
Why does the dataset design matter for real-world deployment?
What future modeling changes target the biggest remaining uncertainties?
Review Questions
- What specific forms of imbalance (subject identity and class frequency) can cause misleading performance in seizure prediction, and how does subsampling address them?
- How do precision-recall results change the interpretation of a model that might look acceptable under accuracy or ROC-AUC alone?
- Why might a one-hour prediction horizon be unreliable, and what multi-horizon or hierarchical strategies are proposed to handle that?
Key Points
- 1
Seizure prediction is framed as a classification problem using pre-seizure neural signals converted into spectrograms.
- 2
The dataset uses canine intracranial voltage recordings from multiple electrodes, with labels based on windows up to one hour before seizure onset.
- 3
Balancing across both dog identity and class labels is crucial to prevent overfitting and majority-class guessing.
- 4
A ResNet-18 trained from scratch achieves about 69% accuracy on the balanced dataset, with ROC-AUC around 0.77.
- 5
High-recall targets come with a false-alarm cost: catching 99% of seizures corresponds to roughly 55% precision in the reported precision-recall trade-off.
- 6
Planned improvements include hyperparameter tuning, regularization, alternative architectures (e.g., larger ResNets or sequence models), and better preprocessing.
- 7
Future work also targets realistic deployment by adapting to less invasive EEG and by modeling electrode correlations and multiple prediction horizons.