Transformer Circuits Part 1
Based on West Coast Machine Learning's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Residual connections make Transformer blocks act like additive corrections to a baseline representation, which simplifies circuit interpretation.
Briefing
Transformer circuits work centers on a simple but powerful claim: even in a stripped-down, one-layer attention-only Transformer, the model’s behavior can be decomposed into two interpretable “circuits”—an output value circuit that predicts how attending to a token changes the next-token logits, and a query-key circuit that predicts which tokens get attended to which others. That decomposition matters because it turns an opaque neural network into something closer to a set of mechanical rules: attention chooses sources, and learned linear maps decide how those sources shift the probability distribution over the vocabulary.
The discussion begins with a fast refresher on the Transformer architecture. Attention blocks (orange) sit alongside feed-forward networks (blue), and residual connections wrap both attention and feed-forward sublayers so that information flows forward even if learned weights are effectively zero. With stacked layers, the model repeatedly transforms a residual stream. For language modeling, tokens start as integer IDs (e.g., 0 to 49,999 for a 50,000-word vocabulary), get turned into vectors via an embedding matrix, and then produce a softmax over the vocabulary to predict the next token.
From there, the focus shifts to progressively simpler “toy” Transformers to make the math tractable. A “zero-layer Transformer” is treated as the simplest baseline: token IDs are embedded and then mapped through a product of embedding and unembedding matrices, yielding an approximation of bigram statistics. The key takeaway is that larger Transformers always contain a term with the same structure—an embedding-to-unembedding path—so understanding this baseline helps interpret what remains when attention is added.
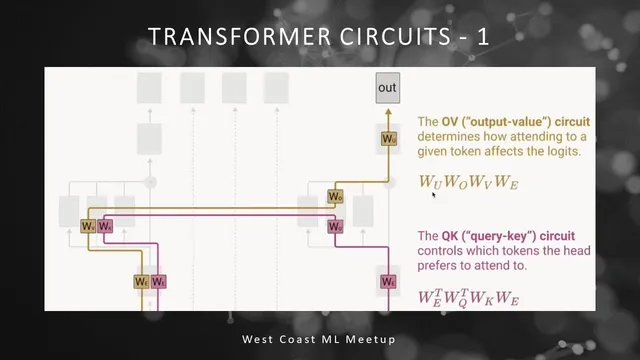
The next step is the “one-layer attention-only Transformer,” which removes MLPs and simplifies away layer normalization and biases to reduce bookkeeping. At a high level, the model does three things: embed tokens, run each attention head and add its result into the residual stream, then map the final residual stream back to vocabulary logits via the unembedding matrix. Inside an attention head, the mechanism is described using matrices for values (from the residual stream via WV), attention weights (from queries and keys), and an output projection (WO) that decides how the attended information is written back into the residual stream.
A major conceptual move is to treat the full attention computation as a structured linear algebra object. By using tensor-product notation, the analysis separates “what attention moves” from “where it moves it.” In this framing, the query-key side determines an attention pattern across token positions (which token attends to which other token), while the value/output side determines how the attended token’s content changes the output logits. When the attention pattern is treated as fixed, the remaining computation becomes linear, allowing the model’s effect to be written as an identity term plus a sum of circuit terms.
Two specific matrices become central. The output value circuit is effectively a vocabulary-by-vocabulary matrix formed from the embedding, value, output projection, and unembedding weights; it quantifies how attending to a particular token would bump or suppress specific vocabulary logits. The query-key circuit is another vocabulary-by-vocabulary matrix that yields pre-softmax attention affinities between token pairs, acting like a lookup table for which words are likely to attend to which others. The analysis notes that positions can matter in real models, but the simplified treatment initially ignores positional embeddings.
The session ends by emphasizing that this is a “lift the hood” approach: fully reverse-engineering a toy Transformer provides interpretability tools, even though multi-layer Transformers introduce more complex interactions. The next step is to test whether the predicted circuit behavior shows up in trained one-layer attention-only models and then extend the method to deeper architectures where interactions go beyond simple word-to-word affinity.
Cornell Notes
The core idea is to interpret a Transformer by splitting its one-layer attention-only computation into two circuits. The query-key circuit determines an attention pattern—how strongly each token attends to every other token—via learned projections of the residual stream into keys and queries. The output value circuit determines what happens to the vocabulary logits when a token is attended to, via a learned chain of embedding/value/output/unembedding maps that can be collapsed into a vocabulary-by-vocabulary linear effect. Treating the attention pattern as fixed makes the remaining computation linear, enabling a clean decomposition into an identity-like direct path plus attention-driven correction terms. This matters because it turns next-token prediction into a mechanical story: attention selects sources, and learned linear maps decide how those sources shift probabilities.
What does the “residual stream” do, and why does the residual connection matter for interpreting Transformer circuits?
Why is the zero-layer Transformer useful when studying deeper Transformers?
In a one-layer attention-only Transformer, what are the three high-level steps from tokens to logits?
How do the query-key and output value circuits differ in what they explain?
Why does treating the attention pattern as “fixed” make the model easier to analyze?
What does the vocabulary-by-vocabulary output value matrix mean operationally?
Review Questions
- In the one-layer attention-only Transformer, which learned matrices determine (a) attention weights across tokens and (b) how attended information changes vocabulary logits?
- How does the identity/direct path in the circuit decomposition relate to the zero-layer Transformer’s bigram-like behavior?
- What changes in the analysis when positional embeddings are included rather than ignored?
Key Points
- 1
Residual connections make Transformer blocks act like additive corrections to a baseline representation, which simplifies circuit interpretation.
- 2
A zero-layer Transformer provides a baseline embedding-to-unembedding path that resembles bigram statistics and appears as a direct term in deeper models.
- 3
A one-layer attention-only Transformer removes MLPs and (for analysis) layer norms and biases to make the computation decomposable into interpretable parts.
- 4
The query-key circuit determines the attention pattern across token positions by projecting the residual stream into keys and queries and applying softmax to dot-product scores.
- 5
The output value circuit determines the logit impact of attending to a token, collapsing learned projections into a vocabulary-by-vocabulary linear effect.
- 6
Assuming the attention pattern is fixed turns the remaining computation into a linear map, enabling a clean decomposition into a direct term plus attention-driven correction terms.
- 7
The next analytical step is to verify whether these predicted circuit behaviors show up in trained one-layer attention-only models before extending to multi-layer interactions.