Tree of Thought Prompting
Based on West Coast Machine Learning's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
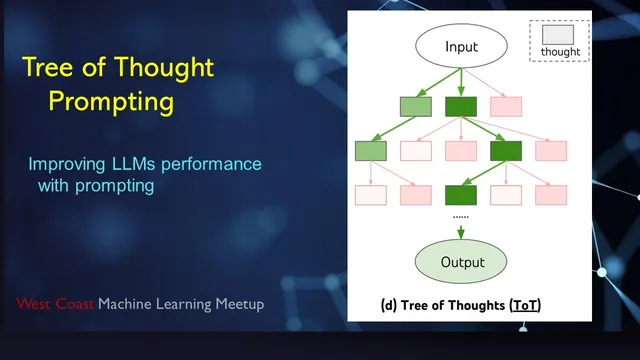
Tree of Thought treats intermediate reasoning as a tree search: generate candidate next steps, evaluate them, expand the best branch, and prune dead ends.
Briefing
Tree of Thought prompting reframes large language model problem-solving as an explicit search process: generate candidate intermediate “thoughts,” score them with a critic, then expand the most promising branches while pruning dead ends and backtracking when progress stalls. The core claim is that this deliberate tree search can outperform straightforward Chain of Thought and related sampling-based methods on tasks where backtracking and multi-step exploration matter—especially puzzle-like, constraint-heavy problems.
The discussion starts by contrasting standard prompting (“input-output prompting”) with Chain of Thought prompting, where models are instructed to write intermediate steps before giving an answer. Chain of Thought often helps because it gives the model a scratchpad and more tokens to compute with, even though it still runs in a single inference pass. Self-consistency is then mentioned as a related technique: sample multiple Chain of Thought solutions and pick the best output via voting, which improves robustness but still lacks active search.
Tree of Thought changes the workflow. Instead of committing to a single linear sequence of intermediate steps, it treats each intermediate state as a node in a tree. A “thought generator” produces one-step candidates (or a small batch of them) using the language model. A “state evaluator” then asks the model to judge how good each candidate is—either by scoring, labeling, or voting among options. The algorithm repeatedly expands the highest-valued node, pruning low-value branches. If all candidates under a node look bad, the method backtracks to an earlier state and tries alternative continuations. The approach is described as a classic tree search (often depth-first), but implemented with language-model generation and language-model evaluation.
Where the method gets practical is in the evaluation tasks. Three benchmarks are highlighted: the game of 24 (using arithmetic expressions to reach 24 from four numbers), mini crosswords (filling a letter grid consistent with across/down constraints), and a crossword-style word/letter constraint setting where partial fills can be invalidated later. The key advantage is that crossword filling naturally benefits from backtracking: an early guess can force later letters to conflict, and the search can discard inconsistent branches.
A major caveat raised during the discussion is that the impressive results rely heavily on prompt engineering and injected constraints. For example, when filling crossword entries, the system doesn’t just ask for “the next word”; it supplies structured, letter-level constraints into subsequent prompts (e.g., forcing a candidate to match already-filled letters). Critics argue this makes the comparison less about general reasoning and more about how much handcrafted guidance is embedded in the prompts and evaluators. The counterpoint is that even if the constraints are engineered, the method still demonstrates a useful pattern: language models can act as both generators and critics inside algorithmic search.
The conversation ends with broader implications: Tree of Thought is positioned as a step toward mixing LLMs with traditional algorithms—turning “reasoning” into something that can be orchestrated like programming (DFS/BFS, pruning, backtracking). But the next leap toward a truly general problem solver would require reducing reliance on problem-specific, hand-injected intermediate prompting and moving toward a single, more universal instruction that governs generation and evaluation across tasks.
Cornell Notes
Tree of Thought prompting turns intermediate reasoning into an explicit tree search. It generates candidate one-step “thoughts,” then uses the language model as a critic to score or vote on which partial states look most promising. The method expands the highest-valued node, prunes low-value branches, and backtracks when all continuations under a node fail—mirroring depth-first search with pruning. This can outperform linear Chain of Thought and self-consistency on tasks where backtracking is essential, such as the game of 24 and crossword-style constraint filling. A key limitation is that strong performance depends on carefully engineered, problem-specific prompts that inject constraints (like letter positions), raising questions about how general the reasoning improvement really is.
How does Tree of Thought differ from Chain of Thought in the way it uses intermediate steps?
Why does the method rely on a “critic” (state evaluator) rather than only sampling more solutions?
What does backtracking look like in the Tree of Thought process?
Why are crossword-style tasks a natural fit for Tree of Thought?
What criticism is raised about how much Tree of Thought’s success depends on prompt engineering?
What would be required for Tree of Thought to feel more like a general problem solver?
Review Questions
- In what ways does Tree of Thought’s decision-making differ from self-consistency when both use multiple samples from a language model?
- Explain how pruning and backtracking are triggered in Tree of Thought. What role does the state evaluator play?
- Why might prompt-injected constraints make crossword results less convincing as evidence of general reasoning improvements?
Key Points
- 1
Tree of Thought treats intermediate reasoning as a tree search: generate candidate next steps, evaluate them, expand the best branch, and prune dead ends.
- 2
Chain of Thought typically runs as a single linear generation, while Tree of Thought actively stops after each step to decide what to do next.
- 3
The state evaluator can score, label, or vote on candidate partial states, enabling pruning based on relative promise rather than only final answers.
- 4
Crossword-style constraint tasks benefit because early guesses can invalidate later choices, making backtracking essential.
- 5
A major limitation raised is that strong performance may depend on handcrafted, problem-specific prompt constraints (e.g., letter-position constraints) rather than purely emergent reasoning.
- 6
The method is positioned as a bridge between LLMs and classic algorithms, where language models act as generators and critics inside DFS/BFS-like search loops.