Tune hyper-parameters (6) - Troubleshooting - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
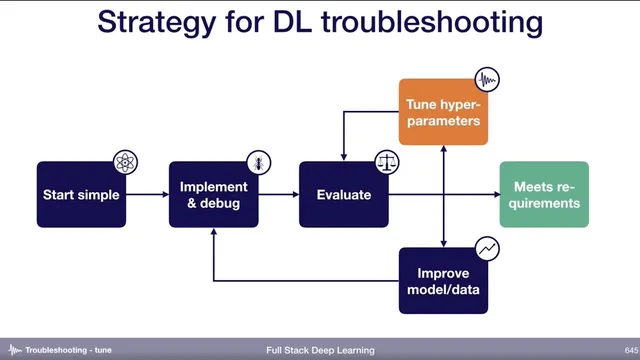
Hyper-parameter tuning is necessary once training and validation errors are close, but it’s difficult because many interacting knobs exist across architecture, optimizer, and training settings.
Briefing
Hyper-parameter tuning is the last major lever after training and validation curves look “reasonably close,” but it’s hard because there are many possible knobs—ranging from the network architecture (e.g., choosing ResNet) to layer depth, initialization, convolution kernel sizes, optimizer settings (like Adam’s beta1, beta2, epsilon), batch size, learning rate, learning rate schedules, and regularization. The practical challenge isn’t just volume; it’s that different models and datasets react to different hyper parameters, and the only reliable way to learn which ones matter is to test multiple settings and build intuition about sensitivity.
A key rule of thumb is that many models are especially sensitive to learning rate and the learning rate schedule. That sensitivity often shows up more strongly than changes to the “shape” of the model itself, so it’s frequently more productive to tune the loss function and layer sizing (for example, whether layers use 64 vs. 256 units) than to start by swapping architectures. Another nuance: sensitivity is measured relative to default values. If weights are initialized in a pathological way (like all zeros), changing initialization can cause a dramatic jump; with sensible defaults, initialization may matter less.
Once the set of hyper parameters is chosen, the transcript lays out several optimization strategies, each with tradeoffs in compute cost, ease of implementation, and how quickly the search narrows.
Manual tuning is the starting point for skilled practitioners: understand how changes affect training dynamics (e.g., higher learning rates can speed convergence but reduce stability), run a small number of experiments, and adjust based on learning curves. It can be compute-efficient, but it demands deep algorithm knowledge and is time-consuming.
Grid search is straightforward but inefficient: it evaluates every cross-combination in a predefined range, which becomes expensive as soon as more than two hyper parameters are involved. Random search samples points within ranges instead of exhaustively enumerating the grid; it’s easy to implement and often finds better results than grid search, but it can feel messy and still depends on choosing sensible ranges.
To improve random search, “coarse-to-fine” random search repeats the process: sample broadly, keep the best-performing region, then resample within that narrower range. This approach is described as widely used in practice because it quickly homes in on good settings while staying relatively simple.
For more hands-off tuning, Bayesian hyper-parameter optimization maintains a probabilistic model linking hyper-parameter choices to performance, then iteratively selects new trials expected to improve results. It can be powerful but is harder to implement from scratch and may be difficult to integrate, so the recommended workflow is to start with coarse-to-fine random search and consider Bayesian methods later as the codebase matures.
In the Q&A, practical guidance emphasizes using prior knowledge to set ranges (e.g., borrowing learning rate ranges from tutorials or papers on similar tasks), starting wide on a log scale when uncertain, and using warm-up learning rate schedules especially when scaling to large batch sizes or distributed training. Differential learning rates are mentioned as useful mainly in fine-tuning scenarios. Cross-validation is generally discouraged in deep learning when data is abundant and training is expensive, while population-based training is highlighted as a genetic-algorithm-like alternative that has shown strong results. Noise in validation can mislead hyper-parameter selection, and the pragmatic response offered is to largely ignore it in practice, relying on robust search strategies.
Cornell Notes
Hyper-parameter tuning matters most after training and validation errors are already close, but the search is difficult because many knobs interact: architecture choices, layer depth, initialization, convolution kernel sizes, optimizer settings (e.g., Adam’s beta1/beta2/epsilon), batch size, learning rate, schedules, and regularization. Many models are especially sensitive to learning rate and its schedule, so tuning those often yields larger gains than swapping architectures. A practical workflow starts with coarse-to-fine random search: sample broadly, keep the best region, then resample within it. As projects mature, Bayesian hyper-parameter optimization can reduce manual effort by using a probabilistic model to guide new trials, though it’s harder to implement and integrate. Range selection benefits from prior knowledge; when uncertain, start wide on a log scale and then zoom in.
Why is hyper-parameter tuning so challenging even when training/validation curves look good?
Which hyper parameters tend to drive the biggest performance changes, and why does that matter?
How do manual tuning, grid search, and random search differ in practice?
What is coarse-to-fine random search, and why is it popular?
When does Bayesian hyper-parameter optimization become a good next step?
What practical tactics help set learning-rate ranges and stabilize training at scale?
Review Questions
- What makes hyper-parameter sensitivity difficult to predict, and how does the recommended approach address that uncertainty?
- Compare grid search and random search in terms of compute cost and how they scale with the number of hyper parameters.
- Why is warm-up particularly important when scaling to very large batch sizes in distributed training?
Key Points
- 1
Hyper-parameter tuning is necessary once training and validation errors are close, but it’s difficult because many interacting knobs exist across architecture, optimizer, and training settings.
- 2
Learning rate and learning rate schedules are often the most sensitive hyper parameters, so they frequently deserve early tuning attention.
- 3
Sensitivity depends on the baseline: changes from pathological defaults (like all-zero initialization) can dominate, while sensible defaults can reduce sensitivity to some choices.
- 4
Coarse-to-fine random search is a practical default: sample broadly, keep the best region, then resample within it repeatedly.
- 5
Grid search becomes inefficient as the number of tuned hyper parameters grows due to the cross-product of combinations.
- 6
Bayesian hyper-parameter optimization can reduce manual effort later, but it’s harder to implement and integrate, so it’s best introduced after the workflow stabilizes.
- 7
Range selection should use prior knowledge when available; otherwise, start wide on a log scale and narrow based on results, and use learning-rate warm-up for large-batch/distributed training.