Turn Your VS Code Into A Generative AI Prompt IDE for RAG Applications
Based on Chat with data's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
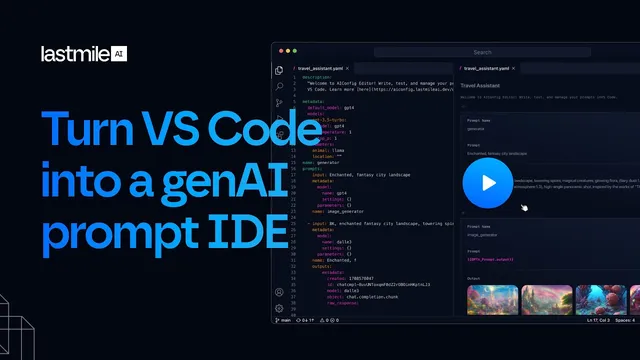
AI config stores prompts, model providers, and settings in version-controlled AI config.yml/AI config.js files, making deployed behavior reproducible.
Briefing
Generative AI teams can turn VS Code into a “prompt IDE” for RAG by using AI config: prompts, model choices, and runtime settings live in version-controlled JSON/YAML files, then run and evaluated through an SDK. The practical payoff is faster iteration—prompt changes can be tested inside the same development environment where application logic is built—plus a more reliable path to production because the exact model and prompt configuration behind deployed behavior can be traced over time.
Last Mile AI frames the problem as a full-stack bottleneck: many engineers building generative applications aren’t ML specialists, yet they still need dependable prompt and model management. AI config addresses that by separating “business logic” code from “generative AI signature” artifacts. In practice, the VS Code extension renders any AI config.yml or AI config.js file as a notebook-style editor. That editor supports prompt templates (including handlebar-style parameter injection), model selection across providers, and multimodal workflows—so prompt exploration happens alongside application development rather than in a separate playground.
The walkthrough builds a simple RAG question-answering app over a large text source (a “volume 7” history-of-the-United-States file). A Python notebook ingests the text by chunking it into fixed-size 1,000-character segments and stores embeddings in a Chroma vector database. Queries then retrieve relevant context and feed it into a generation prompt running GPT 3.5 turbo. Early results illustrate why evaluation matters: a baseline prompt produced an incorrect claim about the price of flower in Boston (July vs. August), showing that retrieval/context alignment and prompt behavior can fail even when the pipeline runs.
Evaluation is handled with model-graded eval using GPT-4. The system measures four criteria: relevance (answers match the question), coherence (readability), faithfulness (answers adhere to retrieved context), and succinctness/structure (responses meet formatting and brevity expectations). Evaluation prompts accept the query, the generation output, and—where needed—the retrieved context. The workflow also highlights a key limitation: GPT-4-based grading is expensive and not perfectly reliable, so prompt engineering for the evaluator still requires iteration.
To move beyond one-off “ad hoc” checks, the approach emphasizes running the same query multiple times (trials) because LLM outputs are nondeterministic unless seeds are controlled. With repeated runs across many queries, teams can compute statistically meaningful distributions of scores rather than trusting a single sample. The next step—still work in progress—is closing the loop from metrics to optimization: specifying an optimization target (e.g., improve faithfulness) and automatically sweeping prompt/model parameters, similar to hyperparameter tuning.
AI config also supports multimodal prompt chains. Examples include using Hugging Face tasks for image-to-text and then feeding generated captions into downstream LLM prompts for translation, or chaining local inference with remote models. Under the hood, attachments and modality-specific outputs are abstracted so developers don’t need to manually handle base64 images, audio formats, or provider-specific invocation logic.
Overall, AI config positions evaluation and prompt management as the missing “debugger-like” layer for RAG pipelines—one that can reduce hallucinations and cost by making quality measurable, repeatable, and versioned, while enabling rapid experimentation in the same IDE used to ship the application.
Cornell Notes
AI config turns VS Code into a notebook-style prompt IDE for RAG and other generative AI workflows. Prompts, model settings, and parameters are stored in version-controlled AI config.yml/AI config.js files, then executed via an SDK so prompt iteration happens inside the same environment as application code. A RAG example ingests a large text file into a Chroma vector database, retrieves context, and generates answers with GPT 3.5 turbo. Quality is then measured using model-graded eval with GPT-4 across relevance, coherence, faithfulness, and succinctness/structure, using the query, model output, and (for faithfulness) retrieved context. Repeated trials across many queries provide more reliable metrics than one-off checks, and future work aims to optimize prompts/settings automatically based on evaluation targets.
How does AI config make prompt development and application development work together instead of in separate tools?
What does the RAG pipeline look like in the walkthrough, and where does evaluation fit?
Why did the baseline RAG prompt fail in the example?
What are the four evaluation criteria used for model-graded eval, and how are they computed?
How does the workflow improve reliability beyond one-off evaluation?
What’s the proposed path from evaluation results to better prompts, and what’s missing today?
Review Questions
- How would you design an eval prompt for faithfulness so it checks specific facts from retrieved context rather than using a vague rubric?
- What changes in your evaluation strategy when GPT-4 grading is too expensive to run across hundreds of queries and many trials?
- In a production RAG system, how could you use logged user queries and stored retrieved context to run eval prompts without rerunning retrieval at evaluation time?
Key Points
- 1
AI config stores prompts, model providers, and settings in version-controlled AI config.yml/AI config.js files, making deployed behavior reproducible.
- 2
The VS Code extension renders AI config files as notebook-style editors so prompt iteration happens inside the same IDE used for app development.
- 3
RAG quality can be measured with model-graded eval across relevance, coherence, faithfulness, and succinctness/structure using GPT-4 as the grader.
- 4
Faithfulness evaluation requires passing retrieved context into the evaluator, and it often remains partly subjective—prompt engineering still matters.
- 5
Reliable evaluation needs repeated trials because LLM outputs are nondeterministic; charting distributions across many queries beats one-off checks.
- 6
A key gap remains automated optimization from eval metrics to improved prompts/settings; the target is an optimization/sweep workflow similar to hyperparameter tuning.
- 7
AI config supports multimodal prompt chains, enabling workflows that combine Hugging Face tasks (e.g., image-to-text) with LLM steps (e.g., translation) without writing provider-specific invocation code.