Versioning (5) - Data Management - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Treat training data as a first-class dependency: deployed ML artifacts depend on both code and the exact dataset used for training.
Briefing
Versioning in machine learning isn’t just about saving model code—it’s about making the trained artifact reproducible by tracking the exact data used to train it. Without data versioning, teams eventually lose the ability to recreate a previously working model: data changes after deployment, but the system only remembers the code hash, not the dataset state that produced the model. The result is a slow drift into irreproducible performance, where retraining may no longer recover the earlier “known-good” model because the original training inputs can’t be reconstructed.
A practical way to think about versioning is in four layers. At the lowest level is “unversioned” data—keeping datasets only in a file system, S3, or a database and training on whatever happens to be there later. The next level adds a snapshot: store a hash or snapshot of the training data alongside the code version so the deployed artifact can be tied to a specific dataset state. But doing this as a crude “snapshot everything” approach can become hacky, especially if it doesn’t capture the full code bundle or if it’s too heavy to manage.
Level two is more systematic: version data as a combination of assets and code. For example, speech datasets might store WAV files in S3 under unique IDs, while labels live in a JSON mapping those IDs to annotations. Those label files can be tracked in version control, but they may balloon into multi-gigabyte blobs when there are millions of labeled rows. Tools like Git Large File Storage (Git LFS) address this by keeping large files out of the Git repository: commits store hashes and pointers while the actual content is uploaded to S3. An additional optimization, lazy data loading, can prevent downloading entire large repositories until the data is actually needed.
In this setup, the dataset version becomes the hash of the underlying raw data and labels—so any change to labels, added rows, or modified waveform files produces a new dataset hash and therefore a new dataset “version.” Adding a timestamp can make it easier to correlate versions with training runs.
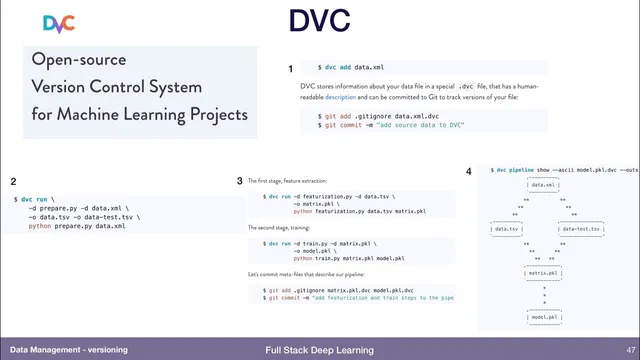
Level three points to specialized machine-learning data versioning systems. The transcript flags a key caution: these tools should be adopted only after understanding the specific problem they solve, because some quickly expand into managing infrastructure and pipelines. Examples mentioned include DVC, which version-controls both data and transformation steps via pipelines (useful in tabular/CSV-style workflows), and Pachyderm, which emphasizes language-agnostic data versioning plus automated triggering, parallelism, and resource management. Another option highlighted is Dolt from Liquid Data, which focuses on database versioning: it provides Git-like branching and merging for databases, supports conflict detection and resolution, and enables comparisons of performance across different dataset versions by running models against each version.
The core takeaway is straightforward: reliable deployment requires treating training data as a first-class, versioned dependency—ideally with tooling that can reproduce both the dataset state and the transformations that produced the training inputs.
Cornell Notes
Machine learning deployments need reproducible artifacts, which requires versioning not only code but also the exact training data. Without tracking dataset state, later retraining may never recreate a previously working model because the data has changed and the original inputs weren’t recorded. A four-level framework starts with unversioned data, moves to snapshot-based tracking, then to asset-plus-code dataset versioning (often using Git LFS and lazy loading for large label files). Specialized tools like DVC, Pachyderm, and Dolt offer deeper data/version workflows, but adoption should match the team’s specific needs—especially since some tools also take on infrastructure management.
Why does missing data versioning eventually break the ability to reproduce a working model?
What’s the difference between snapshotting data and versioning data as assets plus code?
How does Git LFS help when label files become multi-gigabyte?
What does “lazy data” add to dataset versioning workflows?
How do specialized tools differ in their approach to data versioning?
What caution should guide choosing a specialized data versioning tool?
Review Questions
- What two components must be versioned to make a deployed ML artifact reproducible, and what failure mode occurs if one is missing?
- How does hashing raw data and labels create a dataset version, and what kinds of changes would alter that hash?
- Compare DVC, Pachyderm, and Dolt in terms of what they version and how much infrastructure management they appear to assume.
Key Points
- 1
Treat training data as a first-class dependency: deployed ML artifacts depend on both code and the exact dataset used for training.
- 2
Unversioned datasets lead to irreproducibility because later data changes prevent recreating earlier “known-good” models.
- 3
Snapshot-based tracking improves reproducibility by tying a code hash to a dataset snapshot, but can become unwieldy if handled as a blunt blob dump.
- 4
Asset-plus-code dataset versioning works well when large assets (e.g., WAV files in S3) and label metadata (e.g., JSON mappings) can be tracked together via content hashes.
- 5
Git LFS keeps large label files out of the Git repository by uploading content to S3 and storing hashes/pointers in Git.
- 6
Lazy loading reduces the cost of working with large versioned datasets by downloading only what’s needed.
- 7
Specialized tools (DVC, Pachyderm, Dolt) can automate deeper workflows, but should be chosen only when their benefits match the team’s specific problem and infrastructure preferences.