Webinar: GraphQL Federation and Knowledge Graphs
Based on Ontotext's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
GraphQL Federation provides a single, unified GraphQL interface over multiple knowledge-graph services, even when data is split across different backends.
Briefing
GraphQL Federation is positioned as a practical way to turn a set of separate knowledge-graph services into one unified, queryable graph—without forcing clients to know where each piece of data lives. The core idea is to expose each backend (RDF graph database, annotation store, semantic similarity index, and more) through GraphQL, then use federation to stitch them together into a single schema and a single query language. The result is a “single view” over multiple services, where a client can ask for nested, cross-domain data in one request and receive a consistent response shape.
The session grounds that concept in Ontotext’s stack for knowledge graphs. It describes an RDF layer in GraphDB, plus supporting components such as MongoDB for storing text-analytics outputs (notably Web Annotation JSON-LD) and a semantic vector space index for similarity search. A semantic object service sits on top of RDF and other stores, abstracting RDF “in various flavors” behind GraphQL. From a lightweight object model (expressed in a YAML-like representation), the platform can generate GraphQL schemas, resolvers, and the query/mutation surface automatically—then transpile GraphQL queries into high-performance backend queries.
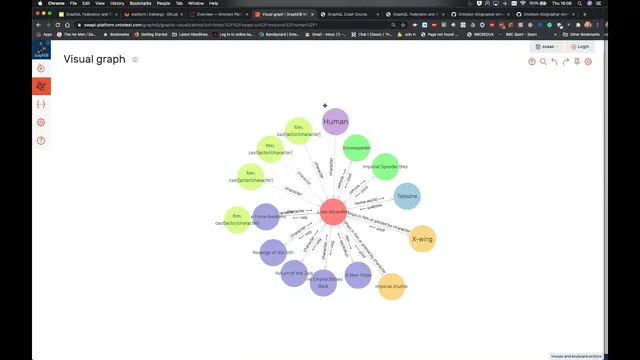
A key portion of the briefing focuses on GraphQL itself as used for knowledge graphs. GraphQL is treated as an API-level query language with strong typing: schemas define object types, properties, arguments for filtering (including complex boolean logic and regex-style matching), pagination, ordering, and mutation operations. The schema also supports interfaces, unions, variables, aliases, fragments, and inline fragments—features that matter when modeling RDF hierarchies such as Star Wars entities (films, characters, species, planets, people). Introspection is highlighted as a way to drive developer tooling: the schema can be queried so IDEs can offer autocomplete and validate query shapes before execution.
Federation then becomes the mechanism for joining isolated graph services. The knowledge graph is split into bounded contexts: one context handles text analytics and stores entity annotations in MongoDB as Web Annotation JSON-LD; another context hosts the Star Wars universe in GraphDB; a third context provides character similarity using a semantic vector space. Federation keys (for example, using a shared identifier like a character URI) define join points across contexts. Extension types let one service “add” fields from another service onto the same conceptual object, so requesting a character can automatically pull in properties from the Star Wars universe, while also attaching similarity-derived relationships.
A concrete example shows how an annotation query can be extended through federation: start with annotations that reference a character URI, then delegate to the similarity service to find similar characters, and finally extend those characters with RDF-backed details such as homeworld, film appearances, and roles. The client-facing query remains simple; the federation engine coordinates schema aggregation, query planning, delegation to each backend, and joining results. The session also notes that federation can handle more than joins—calculations can be federated too, where a field computed in one service depends on data retrieved from another.
Overall, the takeaway is an architecture pattern: model shared entities with stable keys, expose each bounded context through GraphQL, and let federation produce a single aggregated schema and query execution path. That approach supports independent development of services while still enabling one coherent knowledge-graph experience for application developers.
Cornell Notes
GraphQL Federation is presented as a way to unify multiple knowledge-graph services behind one GraphQL endpoint. Each bounded context—RDF data in GraphDB, text-analytics annotations stored as Web Annotation JSON-LD in MongoDB, and semantic similarity built on a vector space—gets its own GraphQL surface, then federation keys and extension types stitch them into a single schema. Strong typing in GraphQL (schemas, arguments, nullable vs non-nullable fields, introspection) helps validate query shapes and reduces runtime mismatches. In the Star Wars example, a client can query annotations, fetch similar characters from the similarity service, and automatically extend those characters with RDF-backed properties like homeworld and film roles. The practical payoff is one declarative query language for cross-service graph data without clients needing to know which backend holds which field.
Why does the architecture rely on GraphQL (and not direct RDF queries) for knowledge-graph access?
What role do federation keys and extension types play in joining separate knowledge-graph contexts?
How does the Star Wars example demonstrate cross-service queries without client-side complexity?
What GraphQL features matter most when modeling RDF hierarchies like characters, films, and planets?
How can federation go beyond joins to support federated calculations?
What does “schema aggregation” mean in GraphQL Federation for this stack?
Review Questions
- How do federation keys and extension types enable a MongoDB-stored Web Annotation JSON-LD entity to be enriched with GraphDB RDF properties in one GraphQL response?
- Which GraphQL schema features (interfaces, unions, fragments, aliases) are most useful for representing RDF subtype differences in the Star Wars model?
- Describe the end-to-end flow of a federated query that starts from annotations, then fetches similar characters, then returns RDF-backed fields.
Key Points
- 1
GraphQL Federation provides a single, unified GraphQL interface over multiple knowledge-graph services, even when data is split across different backends.
- 2
A semantic object service can generate GraphQL schemas, resolvers, and query/mutation surfaces from a simpler object model, then transpile GraphQL into backend queries.
- 3
GraphQL’s strong typing (nullable vs non-nullable fields, schema validation, introspection) helps ensure predictable response shapes and reduces query-shape errors.
- 4
Federation keys (shared identifiers such as character URIs) define join points across bounded contexts like MongoDB annotations, GraphDB RDF, and semantic similarity indexes.
- 5
Extension types let one service add fields from another service onto the same conceptual object, enabling cross-context enrichment in one request.
- 6
Federation can also support federated calculations where a computed field depends on data retrieved from another service.