Why I Prefer Exceptions To Errors
Based on The PrimeTime's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Value-based errors are presented as safer for servers because they force handling at the point of failure, reducing the risk of corrupted intermediate state.
Briefing
The central claim is that exceptions are often a worse fit for building reliable server software than returning errors as explicit values—because value-based errors force developers to decide what to do at the exact point an error can occur, while exceptions can leave programs in an uncertain state if something goes wrong mid-function.
The argument starts from operational reality: server code maintains significant in-memory state and aims for uptime. In that setting, failing one request is preferable to crashing the entire process. Exceptions can unwind the call stack automatically, but the downside is that it’s harder to know where the error was triggered and where it will be caught. With exceptions, a thrown error can bypass local recovery logic and jump to a higher-level handler, potentially skipping cleanup or state correction in intermediate frames. The result, according to this view, is “implicit knowledge” scattered across the stack: developers must trust that the right handler exists above, and that any mutated state in the intervening frames remains valid.
Value-based error handling, by contrast, makes failure part of the function’s contract. If a function returns an error value, callers must handle it immediately—either by propagating it upward, converting it into a default response, or returning a controlled failure to the client (e.g., sending an error message or closing a connection). The pro-exceptions side is acknowledged, but the counter is that “good exception handling” tends to devolve into widespread try/catch blocks anyway, which undermines the idea that exceptions reduce complexity.
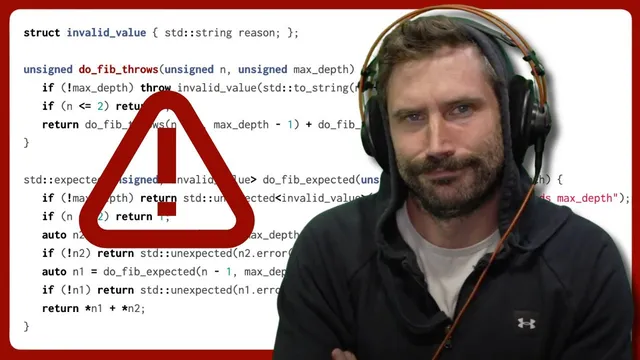
A major thread of the discussion targets performance and overhead. Exceptions are framed as having near-zero cost on the success path because the normal control flow doesn’t need to branch on every call. Error values, on the other hand, require explicit checks and branching, and can introduce heavier “fat” result objects that may hinder optimizations like tail-call elimination. A benchmark example is used to claim C++ exceptions can be dramatically faster than returning error values in a contrived recursive Fibonacci workload, while Rust and C++ “expected/result” style approaches are slower.
Still, the performance debate doesn’t land as a decisive win for exceptions. The counterpoint is that the benchmark is intentionally worst-case and that real systems often avoid the pathological patterns where error propagation becomes expensive. More importantly, the discussion emphasizes that the hardest failures—out-of-memory, stack overflow, integer overflow/underflow—may not be safely recoverable in either model. That’s why some systems adopt “tiger style” programming: assert invariants aggressively (even in production) and design the system so unreachable states are treated as fatal rather than something to recover from.
The closing position is pragmatic: errors as values are favored because they make failure points visible and force deliberate handling, which is crucial for robust services. Exceptions are treated as potentially useful in languages that support them well, but their reputation is described as rooted in historically poor implementations and in the way exception-based control flow can obscure where and how state becomes invalid. The overall takeaway is less about ideology and more about engineering control: knowing exactly which functions can fail, and ensuring the program responds in a controlled, user-visible way without risking hidden corruption of server state.
Cornell Notes
The discussion argues for “errors as values” over exceptions in server-style software. The key reason is control: when errors are explicit in return types, developers must decide immediately how to handle them, which helps prevent corrupted in-memory state when failures occur mid-function. Exceptions can unwind the stack automatically, but that can hide where the failure originated and can force recovery logic to be pushed upward, sometimes requiring try/catch everywhere. Performance is debated with benchmarks claiming exceptions can be faster on success paths, yet the pro-value side counters that real-world code rarely matches the contrived worst cases and that reliability often matters more than micro-optimizations. The conversation also highlights extreme failure modes (OOM, stack overflow) where neither approach guarantees graceful recovery, motivating “assert/tiger style” design.
Why does explicit error-returning (errors as values) get framed as safer for servers with shared in-memory state?
What’s the critique of “catching exceptions at the top” as a general strategy?
How does the discussion connect error handling style to user-visible behavior in server programs?
What performance claims are made, and why are they contested?
What does “tiger style” (assert-heavy) programming contribute to the exceptions-vs-values debate?
How does the discussion treat out-of-memory and other extreme failures?
Review Questions
- What specific reliability problem does the argument claim exceptions can create when errors occur mid-function in server code?
- How do explicit error returns change the developer’s decision-making compared with exception unwinding?
- Why does the conversation say that extreme failures like OOM may require a different strategy than ordinary error handling?
Key Points
- 1
Value-based errors are presented as safer for servers because they force handling at the point of failure, reducing the risk of corrupted intermediate state.
- 2
Exception unwinding is criticized for hiding where failures originate and for relying on implicit assumptions about what intermediate frames did to shared state.
- 3
A “top-level catch” approach is portrayed as insufficient for correctness unless intermediate layers are designed to tolerate unwinding.
- 4
Performance arguments favor exceptions on the success path, but the pro-value side disputes conclusions drawn from contrived benchmarks and emphasizes real-world reliability tradeoffs.
- 5
Extreme failure modes (OOM, stack overflow, overflow/underflow) may be difficult or impossible to recover from cleanly, motivating assert-heavy “tiger style” designs.
- 6
The debate ultimately centers on engineering control: knowing which functions can fail and ensuring failures produce controlled, user-visible outcomes rather than crashes or hidden corruption.