2. Lifecycle - ML Projects - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Plan feasibility and resource needs early by defining goals, scope, and constraints before committing to data collection.
Briefing
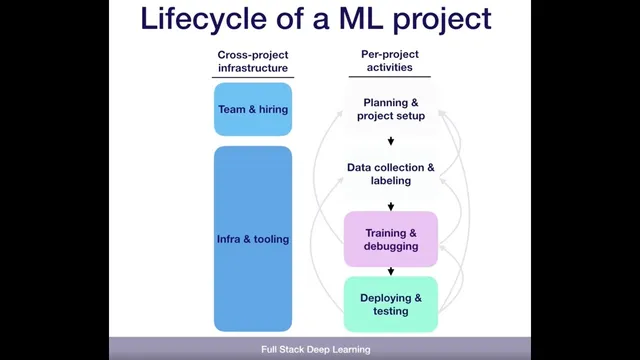
Machine learning projects follow a repeatable lifecycle—planning, data collection, training/debugging, and staged deployment—but progress often loops backward when data quality, labeling, feasibility, or real-world performance falls short. The core takeaway is that success depends less on a straight-line pipeline and more on managing uncertainty: teams must be ready to revisit earlier decisions as new evidence emerges, especially when production results diverge from lab metrics.
The process starts with planning: deciding whether the problem is worth tackling, setting goals, and estimating how many resources the effort will require. For pose estimation, that planning includes defining the scope of objects to recognize and the practical constraints that determine whether the project is feasible. Next comes data collection, which is framed as the most critical phase for machine learning. Teams must capture sensor data—such as camera images—then annotate each image with ground truth pose information (position and orientation) so models can learn from reliable supervision.
A key point is that the lifecycle is iterative rather than linear. After collecting data, teams may discover the task is too hard, data acquisition is impractical, or labeling is the bottleneck. That can trigger a return to planning to rethink the project’s setup. Once labeled data exists, training and debugging begin. Work often starts with a baseline—such as a simple linear regression using OpenCV—then moves toward state-of-the-art approaches found through literature review. Models are implemented, reproduced, and stress-tested on the project’s tasks, with continual improvements until performance meets requirements.
Loops back into earlier phases are common for concrete reasons. Overfitting can force teams to collect more data or redesign the approach. Unreliable labels can produce “garbage” predictions even when training metrics look acceptable. Sometimes the task itself proves infeasible because competing requirements conflict—for example, accuracy versus real-time performance. Even after the model looks strong on collected data, deployment can reveal new failure modes.
Deployment typically happens in stages. A robotics company might pilot in a lab first, then expand toward customer-facing use. During this phase, teams write extensive tests to catch performance degradation quickly. A frequent surprise is that production performance lags behind expectations from offline evaluation. That mismatch can stem from incorrect assumptions about the real-world distribution of objects, leading to underrepresented cases in the training set. Teams may need to gather additional data for hard or rare scenarios.
Finally, metric selection can break down in production. Optimizing a single number—like accuracy—may not translate into improved downstream user behavior. When that happens, teams revisit which metric best reflects the business or user outcome the system is meant to drive.
Beyond the technical loop, organizational enablers matter: hiring strong people, building infrastructure and tooling that keep iteration fast, and maintaining an up-to-date understanding of what’s possible in the domain. Reviewing state of the art is treated as an ongoing capability, often done by starting from landmark results and tracing citations outward and backward to map how progress is built.
Cornell Notes
Machine learning projects move through planning, data collection, training/debugging, and staged deployment, but real progress often requires looping back to earlier phases. Data collection and labeling quality are central, especially for tasks like pose estimation where each image needs ground-truth position and orientation. Training typically starts with a baseline (e.g., linear regression with OpenCV), then improves via literature review and state-of-the-art methods until requirements are met. Deployment frequently exposes gaps: production data distributions differ, labels may not generalize, and a metric that looks good offline may fail to improve downstream user outcomes. Organizational readiness—strong teams, fast infrastructure, and continuous state-of-the-art awareness—determines whether iteration can happen quickly enough.
Why is the lifecycle described as iterative rather than linear?
What makes data collection and annotation so pivotal for pose estimation?
How do baselines and state-of-the-art research fit into training and debugging?
What production failures commonly trigger loops back to training or data collection?
What does staged deployment aim to accomplish?
How can teams review state of the art when starting a new project?
Review Questions
- What specific evidence would justify returning from data collection to planning in an ML project?
- Give two distinct reasons production performance might lag behind offline evaluation, and explain how each would change next steps.
- Why can optimizing a single metric like accuracy fail to achieve the real business goal in deployment?
Key Points
- 1
Plan feasibility and resource needs early by defining goals, scope, and constraints before committing to data collection.
- 2
Treat data collection and ground-truth labeling as a primary risk; pose estimation depends on accurate position and orientation labels per image.
- 3
Expect iteration: new findings after data collection or deployment often require revisiting planning, training strategy, or data acquisition.
- 4
Start training with a baseline to set a minimum bar, then use literature review to move toward state-of-the-art models and debug systematically.
- 5
Use staged deployment and heavy testing to catch performance degradation, but anticipate distribution shifts that offline metrics may miss.
- 6
Reassess both data distribution assumptions and metric choice when production results don’t match offline performance or user outcomes.
- 7
Maintain organizational capabilities—strong hiring, fast tooling, and continuous state-of-the-art awareness—to make iteration practical.