A pretty reason why Gaussian + Gaussian = Gaussian
Based on 3Blue1Brown's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
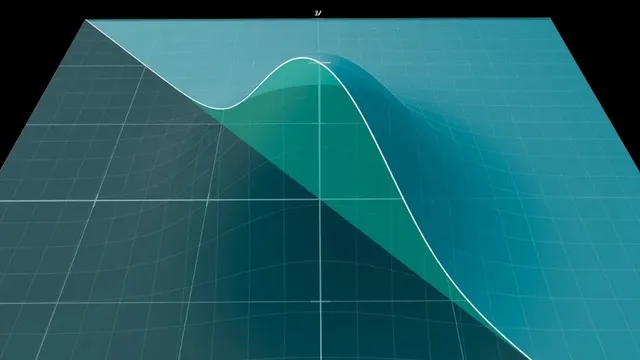
Convolution at s can be interpreted as the integrated probability density over the diagonal slice x+y=s for independent variables.
Briefing
Adding two independent normally distributed variables produces another normal distribution—a “stability” result that explains why the Gaussian is the central shape behind the central limit theorem. The key computation is the convolution of two Gaussian functions, and the payoff is that the convolution’s output keeps the same functional form, with the spread increasing in a predictable way.
The starting point is the simplified bell-curve kernel e^{-x^2}. Convolution asks how likely it is that two independent samples (one drawn from each Gaussian) land on pairs (x, y) whose sum x + y equals a target value s. Geometrically, that probability comes from integrating the product e^{-x^2}e^{-y^2} over the “diagonal slice” of the xy-plane defined by x + y = s. For generic functions, those slices create messy shapes and the integral offers little intuition. Gaussian functions are different: the product e^{-x^2}e^{-y^2} depends only on x^2 + y^2, the squared distance from the origin, which makes the entire 3D surface rotationally symmetric.
That symmetry is the engine of the shortcut. Because the slice x + y = s sits at a fixed perpendicular distance from the origin—specifically s/√2—the diagonal slice area matches the area of a rotated slice. Rotating by 45 degrees turns the problem into one where the slice is parallel to an axis, so one variable becomes constant along the slice. The remaining integral then separates cleanly into an s-dependent exponential factor and an s-independent constant. The s-dependent part becomes e^{-s^2/2}, showing that the convolution has the same bell-curve shape as a Gaussian, just with a different width. The leftover constant is √π (and a technical normalization factor of 1/√2 adjusts the exact convolution value), but the structural conclusion is what matters: convolving two Gaussians yields another Gaussian.
Restoring the full normal-distribution parameters (mean 0 and standard deviation σ) leads to the standard result: the sum of two independent N(0, σ^2) variables is distributed as N(0, (√2 σ)^2). In other words, the standard deviation scales by √2. This is special because most convolution operations do not preserve the original family of functions; they typically produce entirely new shapes.
That specialness also clarifies the central limit theorem’s “why.” The theorem says repeated addition of independent finite-variance random variables tends toward a universal limiting distribution after shifting and rescaling. But the Gaussian’s role isn’t a coincidence or a consequence of the theorem alone: the convolution calculation shows that Gaussians are fixed points under the repeated-convolution process. In a common proof strategy, one first shows convergence to some universal shape for a broad class of starting distributions, then uses the fact that Gaussian-to-Gaussian convolution leaves the Gaussian unchanged to identify that universal limit as the Gaussian itself. The same rotational-symmetry geometry also connects to other derivations of the bell curve and to classic appearances of π, tying the geometry of x^2 + y^2 directly to the central limit phenomenon.
Cornell Notes
Convolution measures how the sum of two independent random variables distributes. For Gaussian kernels e^{-x^2}, the product e^{-x^2}e^{-y^2} depends only on x^2+y^2, giving rotational symmetry in the xy-plane. That symmetry lets diagonal slices x+y=s be treated as rotated, axis-parallel slices at distance s/√2 from the origin, separating the integral into an s-dependent factor and an s-independent constant. The s-dependent factor becomes e^{-s^2/2}, so the convolution of two Gaussians is another Gaussian. With standard deviation σ, the result is that adding two independent N(0,σ^2) variables yields N(0,2σ^2), i.e., standard deviation √2·σ—making Gaussians stable under the convolution step behind the central limit theorem.
Why does the convolution of two Gaussians stay Gaussian instead of turning into a new function?
How does the geometry of the line x+y=s lead to the exponent e^{-s^2/2}?
What role does the constant √π play, and why is it less important than the shape?
How does the result change when the Gaussians have standard deviation σ instead of the simplified e^{-x^2} form?
How does this convolution fact connect to the central limit theorem’s proof strategy?
Why is rotational symmetry described as a “uniquely characterizing” feature of bell curves?
Review Questions
- If the convolution at s is computed via integrating over the slice x+y=s, what geometric quantity determines the slice’s distance from the origin for the Gaussian case?
- What property of e^{-(x^2+y^2)} enables the rotation argument, and how does that simplify the integral?
- In the central limit theorem proof outline, why does showing Gaussian-to-Gaussian convolution act like a fixed point help identify the universal limiting distribution?
Key Points
- 1
Convolution at s can be interpreted as the integrated probability density over the diagonal slice x+y=s for independent variables.
- 2
For Gaussian kernels, the product depends only on x^2+y^2, creating rotational symmetry that makes diagonal slices equivalent to rotated axis-parallel slices.
- 3
The distance from the origin to the line x+y=s is s/√2, which drives the s-dependent exponential term e^{-s^2/2}.
- 4
The convolution of two Gaussians is another Gaussian: adding independent N(0,σ^2) variables yields N(0,2σ^2), so the standard deviation becomes √2·σ.
- 5
Gaussian stability under convolution explains why the Gaussian is the fixed point that the central limit theorem converges toward after rescaling.
- 6
A typical central limit theorem proof strategy uses a universal convergence step (existence of a single limit shape) plus the fixed-point property of Gaussians to identify that limit.
- 7
The same rotational-symmetry geometry links the Gaussian’s form to other derivations and to the appearance of π through a classic integral.