AI code is here. We need to be responsible with it.
Based on Theo - t3․gg's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Treat AI-generated changes as high-risk until behavior is verified; lifecycle mistakes (like firing events on mount) can create immediate cost exposure.
Briefing
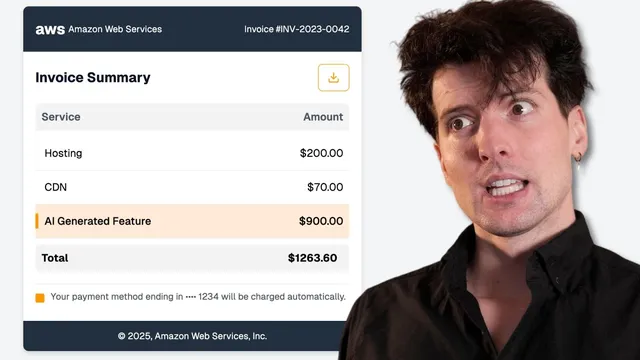
A single AI-generated change triggered a massive analytics bill—millions of Post Hog events in a week—because the code shipped without enough scrutiny. The incident cost $500 in engineering time plus about $733 in event charges, and it became a blunt lesson: AI can produce correct-looking code fast, but teams still need processes that catch subtle mistakes before they hit production and before usage-based meters start running.
The discussion then widens into a practical checklist for surviving an AI-heavy development era. The first pillar is code review culture. AI tools make writing code dramatically easier, which lowers tolerance for “tedious” review work—yet the amount of code entering PRs grows even faster. That mismatch means reviewers often read less carefully, ask fewer questions, and sometimes rely on the assumption that “Claude generated it,” even when the generated logic is wrong or miswired. The recommended fix is cultural, not technical: make code review routine (for example, start and end the day by clearing PRs), treat review as everyone’s responsibility rather than on-call’s, and require engineers to ask questions in PRs—especially “dumb” questions—so uncertainty doesn’t turn into avoidable outages.
A second pillar targets usage-based pricing. When billing scales with real usage, a mistake can become expensive quickly—especially when preview environments, serverless compute, or analytics events spike. The answer isn’t abandoning usage-based systems; it’s adding guardrails around them: spend limits (with an understanding they may cause service disruption), aggressive alerting when thresholds are approached, and clearer “confirm before you burn” flows for high-risk actions like uploading large bandwidth assets. The transcript contrasts this with event-based pricing models that require guesswork (and can lead to either overpaying or losing out when usage changes), arguing that usage-based billing is fairer only if alerts and controls prevent runaway bills.
The third pillar is safety nets—especially one-click rollbacks. Guardrails like tests can warn, but they don’t undo damage. In a world where AI-generated changes can cause production issues or unexpected cost spikes, the ability to instantly revert a bad deploy is framed as non-negotiable for usage-based platforms. The argument is that teams deploy too confidently and roll back too reluctantly; rollbacks should be treated as a normal response to unexpected behavior, not a sign of failure.
Throughout, the incident is used as a lens on analytics and platform responsibility. Post Hog is highlighted for helping with refunds when mistakes happen honestly, and the broader claim is that platforms should do more than meter usage: they should detect problematic spikes, notify users effectively, and design billing communications that don’t create brand-damaging surprises. The bottom line: as AI accelerates coding and increases the volume of changes, companies win by upgrading culture (review and questions), operations (alerts and spend controls), and resilience (instant rollback), not by trying to make AI “smarter” or cheaper.
Cornell Notes
A costly analytics incident traced back to an AI-generated change underscores a core point: faster code generation doesn’t remove the need for disciplined review and operational safeguards. The transcript argues for three defenses against AI-era mistakes—(1) a stronger code review culture that makes thorough reading routine and encourages “dumb” questions, (2) usage-based cost controls via spend limits and high-signal alerts when event or compute spikes occur, and (3) safety nets, especially one-click rollbacks, so teams can instantly undo harmful deploys. Together, these practices reduce both the likelihood of expensive failures and the time to recover when they happen. In a world of more PRs and more automated code, culture and resilience matter as much as tooling.
Why did the analytics bill spike, and what does it imply about AI-generated code risk?
How does AI change the economics of code review, and what should teams do about it?
What does “ask dumb questions” accomplish in PR culture?
Why is usage-based pricing dangerous without alerts and controls?
What’s the difference between guardrails and safety nets, and why does rollback matter most?
How should platforms and analytics providers handle runaway bills and spike detection?
Review Questions
- What specific failure mode (code behavior) led to the event spike, and how could a review process have caught it earlier?
- Which of the three defenses—code review culture, usage-based controls, or safety nets—would you prioritize first for a team adopting AI coding tools, and why?
- How would you design alert thresholds and rollback procedures so that cost spikes and production bugs are both handled quickly without disrupting legitimate viral traffic?
Key Points
- 1
Treat AI-generated changes as high-risk until behavior is verified; lifecycle mistakes (like firing events on mount) can create immediate cost exposure.
- 2
Make code review a daily routine and a shared responsibility; avoid letting on-call become the default reviewer.
- 3
Encourage engineers to ask questions in PRs (including “dumb” ones) and normalize comments as part of learning and risk reduction.
- 4
For usage-based systems, pair spend limits with high-signal alerting so engineers notice threshold crossings before bills become unmanageable.
- 5
Require one-click rollback for usage-based deployments; rollback capability is a resilience requirement, not an optional convenience.
- 6
Platforms should improve spike detection and billing communications to reduce both financial harm and brand damage when usage surges unexpectedly.
- 7
Operational culture matters: teams must be willing to roll back quickly when something unexpected happens, even if the root cause isn’t fully known yet.