All RNNs Come From This One Idea
Based on Artem Kirsanov's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Frame-by-frame processing of video with an image classifier fails because predictions are independent across frames and no temporal context is retained.
Briefing
Most neural networks are “amnesic”: they process each input as if it were new, with no built-in sense of time. That limitation becomes obvious when an image classifier like AlexNet is repurposed for video—shuffling frames leaves its predictions unchanged because each frame is handled independently. Human perception works differently. Watching a movie means the current moment is shaped by what came right before, with context and an “arrow of time” built into how information is interpreted. Recurrent neural networks (RNNs) were created to bake sequence and memory into the computation itself.
The core technical move starts with the standard feed-forward network. In a feed-forward layer, a vector of neuron states is transformed by applying an activation function (the “fire” step) and then mixing signals through a weight matrix (the “project” step). Stacking layers yields a static, one-way mapping: the next state depends only on the previous layer’s current signals, not on anything earlier. In this setup, time is absent because nothing carries forward an echo of past states.
To introduce time, the layer update equation is modified so each time step includes an additional term: an “echo” of the neuron’s previous state. A general memory function M determines how that echo propagates. If M is chosen to mirror the feed-forward transformation—again using activation and a learned projection—then the resulting “vanilla” RNN can retain information only briefly. The reason is structural: every time step repeatedly applies a nonlinear squashing (sigma) and a linear mixing (weights). Over many steps, the original signal gets progressively transformed, like a telephone game where the message is paraphrased each round. The operation that feed-forward networks use for compression—collapsing many variations of an input into a stable representation—gets repurposed to preserve information across long sequences, which it is not designed to do.
A key insight from deeper network design helps fix this. Residual connections let information bypass transformations across layers, preserving important signals while still allowing selective updates. For RNNs, the analogous requirement is a memory pathway where information can flow forward largely intact, with only controlled modifications. The simplest echo that does this keeps a fraction α of the previous state and adds new input. With α=0, the model forgets completely and reverts to the frame-independent behavior. With α=1, it preserves everything, but the state becomes an unstructured running sum—older information never truly disappears, yet it also becomes hard to retrieve.
The practical solution is to make forgetting selective and context-dependent. Instead of a single scalar α shared by all neurons, each neuron gets its own retention gate f_t computed at every time step. A learned “forget gate” (typically produced by a small neural network with a sigmoid output) decides, per neuron, how much of the old state to keep and how much to erase to make room for new information. This gated retention matches the leaky integrated behavior of neurons in computational neuroscience, where charge builds and leaks away.
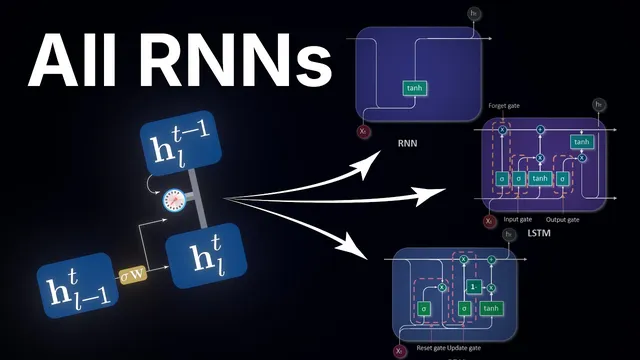
This mechanism underpins gated RNN families—especially GRUs and LSTMs. GRUs combine a forget gate with an update gate, while LSTMs maintain separate internal state vectors to control what is stored versus what is passed along. Underneath the engineering differences is the same principle: adaptive valves that choose what to remember and what to forget. That selective, learned control is what finally enables recurrent networks to learn long-range dependencies, turning “echoes” into usable memory rather than either rapid amnesia or indiscriminate hoarding.
Cornell Notes
Neural networks built as feed-forward systems have no built-in notion of time, so they treat each input independently. When time is added through a vanilla recurrent “echo” term that mirrors feed-forward transformations, information degrades quickly because nonlinear squashing and linear mixing repeat at every step. A better memory mechanism preserves information through a mostly unprocessed pathway, then selectively updates it. Replacing a fixed decay rate with learned, per-neuron forget gates yields leaky, context-dependent retention—older information fades while relevant recent details persist. This gating is the central idea behind GRUs and LSTMs and is what allows RNNs to learn long-range dependencies.
Why does an image classifier like AlexNet fail on video when frames are processed independently?
What goes wrong with vanilla RNNs when trying to learn long-range dependencies?
How does the residual-connection idea translate into recurrent memory?
Why is a fixed scalar retention rate α not enough for real sequences like movies?
What is the role of the forget gate in gated RNNs like GRUs and LSTMs?
Review Questions
- How does the feed-forward layer update equation differ from the recurrent update equation that includes an echo term?
- Explain, using the “repeated squashing and projection” mechanism, why vanilla RNNs struggle with long-range dependencies.
- What changes when α is replaced by a learned, per-neuron forget gate vector f_t, and why does that matter for sequences of varying relevance over time?
Key Points
- 1
Frame-by-frame processing of video with an image classifier fails because predictions are independent across frames and no temporal context is retained.
- 2
Feed-forward networks compute a static transformation: the next state depends only on the previous layer’s current signals, not on earlier history.
- 3
Vanilla RNNs can remember only briefly because repeated application of activation (sigma) and recurrent weight mixing progressively distorts older information.
- 4
A residual-connection-like memory pathway is needed: preserving a fraction of the previous state while adding new input prevents constant reprocessing.
- 5
A fixed scalar decay rate α is too rigid for real sequences; retention must vary by neuron and by time step.
- 6
Learned forget gates implement context-dependent selective forgetting, enabling RNNs to keep relevant details and discard irrelevant ones.
- 7
GRUs and LSTMs differ in their internal wiring, but both rely on the same core idea: adaptive gating that controls what to remember versus what to forget.