Build Local Long-Running AI Agent (Stop Your Agents from Getting Lost) | LangChain, Ollama, Pydantic
Based on Venelin Valkov's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Long-running agent failures often stem from discrete sessions that don’t preserve prior memory, not just model quality.
Briefing
Long-running AI agents often lose their footing as tasks stretch across multiple context windows—hallucinations creep in, code can be rewritten or even deleted, and bugs appear that weren’t present early on. A proposed fix from Anthropic reframes the problem: agents can’t rely on continuous conversation memory, because each new session starts “fresh.” The practical consequence is that resuming work later requires explicit checkpoints that capture what matters, not a running chat history.
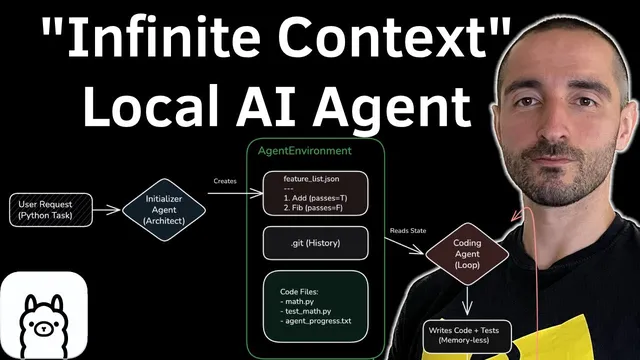
Anthropic’s approach, implemented via its Agent SDK, splits the workflow into two roles to create those checkpoints. An initializer agent runs first to set up the environment and produce a structured “feature list” describing what needs to be built. A separate coding (worker) agent then iterates through that list: for each feature, it generates the implementation and unit tests, runs verification, and records results back into the feature list. Each successful feature becomes an artifact—code files plus updated JSON state—so the worker can continue in later sessions without needing prior message history.
The transcript then walks through a concrete reimplementation of the same idea using LangChain with a local model stack: LangChain 1.1, Ollama, a “q u a n t 3 8 billion parameter” model, and Pydantic for structured outputs. The project is intentionally small but mirrors the checkpoint logic. A shared “agent environment” stores: (1) a feature list JSON with fields like category, description, step-by-step implementation guidance, and pass/fail status; (2) git history context (the last five commits); and (3) a list of code files representing the current project state. Instead of persisting conversation, the coding agent receives only the relevant checkpoint context when it resumes.
In the setup, the initializer agent takes a user request (example: “create Python functions for Fibonacci and factorial include unit tests”), generates the feature list, and commits an initial project state to git. After that, the coding agent runs in a loop with a maximum-attempts retry policy. For each feature marked as incomplete, it is prompted as a “Python developer” with rules like keeping code simple and ensuring tests are runnable. The agent writes the necessary files, executes the test command, and—if tests pass—updates the feature list JSON to mark the feature complete and proceeds to the next item.
A key safety note appears: the environment includes a shell-command runner, which is powerful but risky on machines with important data, so sandboxing is recommended. In the demo run, the initializer produces features for factorial and Fibonacci. The coding agent then implements both functions and their unit tests, and the transcript reports that tests pass and the feature list reflects completion for each. The overall takeaway is that checkpoint-driven progress—anchored in structured JSON state plus git-backed artifacts—can keep long-running agent work consistent even when message history isn’t carried forward.
Cornell Notes
Long-running AI agent tasks can degrade across context windows because each new session lacks prior memory, leading to hallucinations and broken code. Anthropic’s solution creates explicit checkpoints by splitting work into two agents: an initializer that generates a structured feature list and sets up the project, and a coding agent that implements one feature at a time, runs unit tests, and updates the feature list. The coding agent resumes using checkpoint context (feature list JSON, git history, and relevant file state) rather than conversation history. The transcript demonstrates this pattern with LangChain 1.1, Ollama, Pydantic structured outputs, and a local “q u a n t 3 8 billion parameter” model, using git commits and JSON status to track progress reliably.
Why do long-running agents “get lost” even when models improve?
How does the initializer agent create a checkpoint that the worker can trust?
What exactly does the coding agent use as context when resuming?
What is the per-feature workflow inside the coding agent loop?
What safety concern comes with the environment’s command execution?
What did the demo accomplish to validate the approach?
Review Questions
- In what way does session-based memory loss break naive long-running agent workflows?
- How do feature-list JSON status and git commits work together to form resumable checkpoints?
- Why does the coding agent avoid using conversation history, and what does it use instead?
Key Points
- 1
Long-running agent failures often stem from discrete sessions that don’t preserve prior memory, not just model quality.
- 2
Splitting responsibilities into an initializer (planning + environment setup) and a coding agent (implementation + verification) creates reliable progress checkpoints.
- 3
A structured feature list JSON acts as the worker’s source of truth, including implementation steps and pass/fail status.
- 4
Checkpoint context should be derived from artifacts (feature list, code files, git history) rather than conversation history.
- 5
Unit tests are central to the loop: each feature is only marked complete after tests pass.
- 6
Retry logic with a maximum-attempts limit helps recover from failed implementations without losing the overall plan.
- 7
Shell command execution is powerful but should run in a sandbox to prevent damage to important systems.