Consistency Models
Based on West Coast Machine Learning's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Consistency models accelerate diffusion by learning a time-conditioned mapping f_θ that converts an intermediate noisy state x_t directly to the clean sample x_0 in one step (or a few steps).
Briefing
Consistency models aim to cut diffusion sampling time by replacing many denoising steps with a learned, one-step (or few-step) mapping from a noisy sample back to the data. The core idea rests on a mathematical link between diffusion’s stochastic differential equation (SDE) and a deterministic probability-flow ordinary differential equation (ODE): both describe the same evolution of probability densities. Once that bridge is in place, it becomes possible to train a neural network to “jump” along the ODE trajectory—taking an input at an intermediate noise level and producing the corresponding clean sample—without repeatedly evaluating the score model at many time steps.
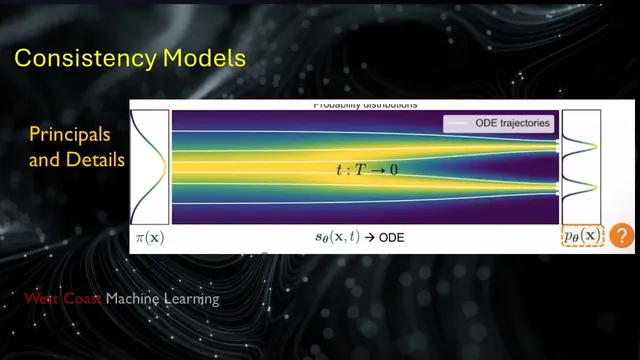
The discussion begins with diffusion’s standard forward process: start from clean data, inject noise gradually until the distribution approaches a simple Gaussian prior, and then reverse the process to generate samples. In continuous time, the forward dynamics are modeled with an SDE whose drift and Brownian-motion terms progressively transform the data distribution into noise. The reverse dynamics are also an SDE, but its drift depends on the score function (the gradient of the log probability density). Training therefore learns a time-conditioned score network by minimizing a score-matching loss at randomly sampled time steps, then sampling uses an SDE solver to integrate the reverse process from Gaussian noise back toward the data manifold.
A key pivot comes from probability-flow ODEs. While the SDE produces stochastic trajectories, the ODE yields a deterministic path whose induced probability density matches the SDE’s at every time. This one-to-one correspondence between the SDE’s distribution evolution and the ODE’s deterministic flow enables a different training target: instead of repeatedly solving the reverse SDE, learn a function that maps directly from an intermediate noisy state to the clean state associated with that point on the ODE trajectory. In the simplest case, the learned function f_θ takes x_t (a noisy sample at time t) and outputs x_0 in a single step, provided the time conditioning is correct.
Consistency models formalize this with two constraints. First is a boundary condition near the smallest time ε: when the input is extremely close to the data, the model should output the same clean sample rather than collapsing to a constant. Second is a self-consistency constraint: for two time stamps t and t′ along the same probability-flow trajectory, applying f_θ at the correct time should return the same x_0. Architecturally, skip connections are used to enforce the ε behavior, and training samples pairs of adjacent (or near-adjacent) points along trajectories.
Training is presented in two main flavors. The more common approach distills from a pre-trained diffusion model: use an ODE solver to generate trajectory points, then train f_θ so that predictions from consecutive times agree on x_0. To stabilize learning and reduce gradient variance, a target network updated via exponential moving average (EMA) is used. The second approach trains a standalone consistency model without relying on a pre-trained diffusion model or an ODE solver, but it tends to be less effective because the added noise is not aligned with the specific trajectory structure.
Finally, sampling can be done in one step for speed, but quality improves with multi-step consistency sampling: repeatedly add analytically computed noise to the current estimate at later time steps and re-apply f_θ. The result is a practical tradeoff—fast generation with a small number of model evaluations—while retaining diffusion’s ability to model complex image distributions. The discussion also notes that consistency ideas extend beyond pixel space into latent-space variants (e.g., latent consistency models) and are already used in real-time image generation demos, though quality depends on the specific variant and training setup.
Cornell Notes
Consistency models speed up diffusion generation by learning a function f_θ that maps a noisy sample x_t at a given time t directly to the clean sample x_0, instead of running many reverse-diffusion steps. The method relies on the relationship between diffusion’s stochastic SDE and the deterministic probability-flow ODE, which preserves the same probability density over time. Training enforces (1) a boundary condition near ε so the model doesn’t collapse, and (2) self-consistency so outputs from different times along the same probability-flow trajectory agree on the same x_0. In practice, distillation from a pre-trained diffusion model uses ODE solvers to generate trajectory pairs and trains f_θ with an EMA target network for stability. Multi-step sampling can further improve quality by iteratively re-noising to intermediate times and re-applying f_θ.
Why does the probability-flow ODE matter for consistency models?
How does consistency training avoid mode collapse (e.g., always predicting the same output)?
What exactly are the two constraints used to define a valid consistency model?
How does distillation-based consistency model training work in practice?
Why can standalone (from-scratch) consistency training underperform distillation?
What’s the role of multi-step sampling in consistency models?
Review Questions
- How does the deterministic probability-flow ODE preserve probability densities compared with the stochastic SDE, and why does that enable learning a direct x_t→x_0 mapping?
- What do the boundary condition near ε and the self-consistency constraint enforce, and how do skip connections help satisfy the ε behavior?
- Compare distillation-based consistency training and standalone consistency training: what information does distillation leverage that standalone training lacks, and how does that affect quality?
Key Points
- 1
Consistency models accelerate diffusion by learning a time-conditioned mapping f_θ that converts an intermediate noisy state x_t directly to the clean sample x_0 in one step (or a few steps).
- 2
Probability-flow ODEs provide a deterministic counterpart to diffusion’s SDE that matches the same probability density evolution over time, enabling trajectory-based “jump” learning.
- 3
Training enforces a boundary condition near ε (to prevent collapse) and a self-consistency constraint so outputs from different times along the same probability-flow trajectory agree on the same x_0.
- 4
Distillation-based consistency models rely on a pre-trained diffusion model plus an ODE solver to generate trajectory pairs, then train f_θ using losses that align predictions across adjacent times.
- 5
An EMA target network is used during distillation training to stabilize gradients and reduce variance.
- 6
Sampling quality improves with multi-step consistency sampling: repeatedly re-noise the current estimate to intermediate times and re-apply f_θ rather than relying on a single jump from pure noise.