Feature Selection in Python | Machine Learning Basics | Boston Housing Data
Based on Ciara Feely's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Correctly encode index-like features (e.g., RAD) as categorical; treating them as numeric can mislead downstream feature selection.
Briefing
Feature selection is used to dramatically improve a K-nearest neighbors regression model on the Boston housing dataset by cutting weak or redundant predictors and then validating the remaining variables with model-based search. Starting from a relatively poor fit (RMSE around 6.5k and R² about 0.5), the workflow targets the “curse of dimensionality” and practical issues like computation time, data-collection cost, and—importantly—model interpretability.
The tutorial first revisits the Boston housing variables and corrects a key preprocessing mistake: the “RAD” feature is an index/label (1–24), so it must be treated as categorical rather than numeric. After encoding categorical levels into dummy variables, the model is re-evaluated. With the corrected encoding in place, the next step is variance-based filtering. Low-variance features are removed because they barely change across samples and therefore contribute little predictive signal. Dropping a couple of low-variance dummy variables yields a modest improvement, but the process is constrained by categorical logic—levels can’t be arbitrarily deleted without breaking the meaning of the encoding.
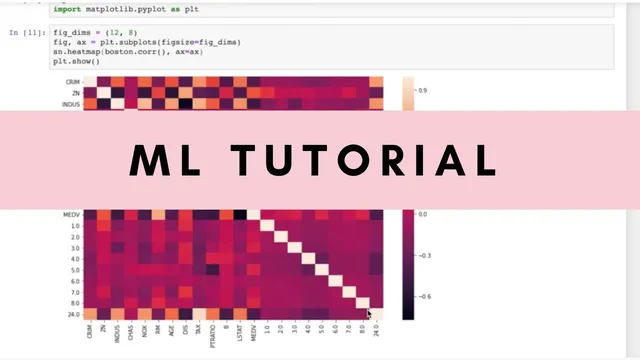
Next comes correlation filtering. Using heatmaps and correlation thresholds, the approach aims to avoid strong multicollinearity among explanatory variables (values around 0.8+ are flagged as risky) while still keeping features that correlate with the target MEDV (median home value). The tutorial experiments with different cutoffs and finds that correlation-only filtering can help, but not always in a principled way. The best early result comes from retaining a small set of variables (RMSE drops to roughly 4.7k and R² rises to about 0.74), suggesting that some RAD levels may be better handled by grouping rather than treating every level separately.
To move beyond classifier-agnostic filtering, the tutorial switches to wrapper-based feature selection using sequential feature selection from scikit-learn’s feature selection tools. Instead of ranking features by correlation, it searches for subsets that optimize model performance directly. In forward selection, the best single feature is LSTAT, followed by number of rooms, crime, and pupil-teacher ratio; backward selection lands on the same core set. Building a model with these selected predictors substantially improves fit (R² climbs to about 0.7–0.75 range, with the tutorial reporting a strong reduction in RMSE).
An interaction term is then tested—specifically multiplying LSTAT and number of rooms—to capture a relationship that correlation alone might miss. The improvement is small but positive, and the tutorial notes that adjusted R² would penalize adding extra variables, so the gain must justify the added complexity.
Finally, the tutorial addresses outliers. It observes that some extreme MEDV values appear capped at 50, creating suspicious “outlier” behavior. After removing those capped points, R² increases further to around 0.8, with the model fit becoming smoother and more plausible. The overall takeaway is that feature selection works best as an iterative pipeline: correct encoding first, then prune by variance/correlation, then validate with wrapper search, and finally refine with interaction terms and outlier handling.
Cornell Notes
The tutorial improves a regression model on the Boston housing dataset by selecting a smaller, more informative set of features. It starts with a baseline K-nearest neighbors regression and corrects preprocessing by treating the RAD index as categorical (dummy-encoded), not numeric. Variance filtering removes near-constant predictors, and correlation filtering avoids multicollinearity while keeping features linked to MEDV. The biggest gains come from wrapper-based sequential feature selection, which chooses subsets based on actual model performance, yielding a compact set including LSTAT, number of rooms, crime, and PTRATIO. Adding an interaction term (LSTAT × rooms) helps slightly, and removing capped extreme MEDV points pushes R² to around 0.8.
Why does treating RAD as categorical (dummy variables) matter for feature selection and model quality?
How does variance filtering decide which features to drop, and why can it be tricky with categorical variables?
What’s the role of correlation filtering, and what multicollinearity risk does it try to avoid?
Why does wrapper-based sequential feature selection often outperform correlation-only filtering?
Which features emerge as the best subset in sequential feature selection, and what does that imply?
How do interaction terms and outlier handling change the model’s performance?
Review Questions
- What preprocessing step is required for RAD, and what error would occur if it were treated as numeric?
- Compare variance filtering, correlation filtering, and sequential feature selection: what does each optimize, and what are the limitations?
- Why might adding an interaction term improve performance even when marginal correlations look weak?
Key Points
- 1
Correctly encode index-like features (e.g., RAD) as categorical; treating them as numeric can mislead downstream feature selection.
- 2
Use variance filtering to remove near-constant predictors, but avoid arbitrary deletion of categorical levels without a principled grouping strategy.
- 3
Apply correlation filtering to reduce multicollinearity risk among predictors and to keep features that relate to the target (MEDV).
- 4
Prefer wrapper-based sequential feature selection when feature interactions matter, since it evaluates subsets using model performance directly.
- 5
Test interaction terms when only a few predictors show meaningful relationships; small gains can still be worthwhile if complexity is controlled.
- 6
Handle outliers thoughtfully—capped or distorted extreme target values can depress R² and worsen learned relationships.
- 7
Validate improvements with consistent metrics like RMSE and R² (and consider adjusted R² when adding features).