How to Compare Multiple Large PDF Files Using AI (w/ Jerry Liu, Co-Founder of LlamaIndex)
Based on Chat with data's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Single-vector-index retrieval can skew toward one document, causing polluted context and unreliable comparisons.
Briefing
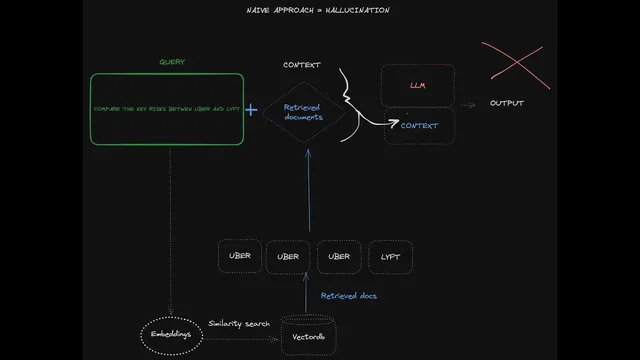
Comparing two huge PDFs with AI—like Uber and Lyft 10-K filings—breaks down when retrieval is done “all at once” in a single vector index. The core fix is to structure the data and the question workflow so the model pulls the right sections from each company separately, then combines the results. Without that structure, similarity search can return an imbalanced mix of chunks (often mostly from one document), polluting the context and leading to incorrect or unhelpful answers.
The transcript starts with a naive retrieval-augmented generation (RAG) setup: chunk both PDFs, embed the chunks, store them in a vector database, then retrieve the top K most similar chunks for a query like “compare the risk factors of Uber and Lyft.” The failure mode is predictable. Vector similarity doesn’t inherently know which chunks belong to which company unless extra metadata filtering is used correctly. In practice, the top-K results can skew heavily toward one document—e.g., three chunks from Uber and one from Lyft—so the language model synthesizes from the wrong evidence. That’s why a “compare and contrast” question can come back with either a refusal (“cannot provide a direct comparison”) or a lopsided answer.
LlamaIndex is presented as a framework for building more reliable RAG pipelines over complex documents, with special emphasis on two advanced cases: multi-document comparisons and embedded tables in PDFs. For multi-document comparison, the approach shifts from a single shared index to separate indexes (or namespaces) per document. Then the system decomposes the original question into sub-questions—such as “describe Uber’s revenue growth in 2021” and “describe Lyft’s revenue growth in 2021”—runs retrieval within each document’s index, and finally merges the sub-answers into a coherent comparison.
A concrete example shows the difference. In the baseline setup, a compare-and-contrast query about risk factors fails because retrieved sources are dominated by Lyft chunks. With the sub-question query engine, the workflow becomes: create a “tool” for each company’s index (Uber financials for 2021; Lyft financials for 2021), let a higher-level query engine decide which tools to use, retrieve within each company separately, and then synthesize. The result is a direct comparison that includes risk factors for both companies.
The transcript also contrasts this structured query planning with function-calling/agent-style strategies. Function calling can be more flexible but may be slower and more failure-prone—especially with weaker models—because it often relies on sequential loops that can spiral into unnecessary iterations. The sub-question approach aims for parallelism and reliability by mapping each sub-question to the specific subset of data it requires.
Finally, the discussion broadens beyond qualitative demos: it recommends defining evaluation benchmarks—candidate questions (including comparison queries) and metrics—then iterating on the retrieval and planning strategy only when quality falls short. The takeaway is pragmatic: for large, messy PDFs, accurate comparison depends less on “bigger prompts” and more on disciplined indexing and question decomposition.
Cornell Notes
AI comparisons across multiple large PDFs fail when both documents are dumped into one vector index and retrieved with top-K similarity. The retrieval step can return an imbalanced set of chunks from only one company, so the language model synthesizes from polluted context and may refuse or produce lopsided answers. A more reliable method indexes documents separately (e.g., Uber vs. Lyft), decomposes a compare-and-contrast question into sub-questions per document, retrieves within each document’s index, then combines the results. LlamaIndex’s sub-question query engine implements this structured query planning using per-document “tools” and parallel sub-queries. This matters for financial analysis tasks like comparing 10-K risk factors or revenue growth across years, where evidence must come from the correct filing sections.
Why does a single shared vector index often break “compare and contrast” questions across two PDFs?
What structured change improves multi-document comparison reliability?
How does the sub-question query engine decide which document-specific retrieval to run?
How is this approach different from function-calling or agent loops?
What does “index” mean in this context, and why does it matter?
What practical step should be taken before adopting advanced comparison strategies?
Review Questions
- In a two-PDF comparison task, what specific retrieval failure leads to hallucinated or refused answers in the naive single-index approach?
- How does decomposing a compare-and-contrast question into sub-questions change the retrieval evidence the model sees?
- What tradeoffs are discussed between structured query planning (sub-question engine) and function-calling/agent-style loops?
Key Points
- 1
Single-vector-index retrieval can skew toward one document, causing polluted context and unreliable comparisons.
- 2
Separate indexing (or namespaces) per document keeps retrieval evidence aligned with each entity being compared.
- 3
Decomposing a comparison query into document-specific sub-questions improves reliability by restricting retrieval to the correct subset of data.
- 4
A sub-question query engine can implement this by treating each document index as a “tool” with descriptive metadata.
- 5
Function-calling/agent loops may be slower and more failure-prone for complex comparisons, especially with weaker models.
- 6
Cost and latency increase because the system performs extra steps: question decomposition, multiple retrievals, and final synthesis.
- 7
Quality improvements should be validated with benchmarks: define candidate questions and metrics before and after adopting advanced techniques.