LangChain Agents: Build Personal Assistants For Your Data (Q&A with Harrison Chase and Mayo Oshin)
Based on Chat with data's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
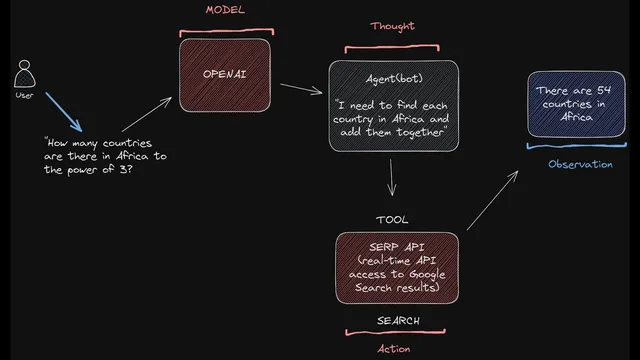
LangChain agents combine tool use with memory: the model reasons, calls tools, ingests observations, and iterates toward a plan.
Briefing
LangChain agents are built around a simple but powerful idea: use a language model as a reasoning engine, then let it reliably choose and run external tools—while maintaining memory of conversations, intermediate steps, and longer-term preferences. The practical payoff is “personal assistant”-style systems that can look things up, execute actions, and update what they know about a user over time, rather than just generating text from a static prompt.
At the core, an agent in LangChain combines two defining capabilities. First is tool use: the model can decide when to call tools such as search engines, arbitrary APIs, Python REPL-style functions, or other external services. After each tool call, the agent ingests the observation—like a search result or an error message—and feeds that back into its planning loop to decide what to do next. Second is memory, which matters because language models are stateless by default. LangChain discusses multiple memory layers: conversational memory to carry context across turns; intermediate-step memory so the agent can reuse results from earlier tool calls during multi-step workflows; and newer “reflection” approaches where the agent updates an internal representation of the world—such as inferring user preferences from changing outcomes (e.g., liking sunny weather and disliking rainy weather).
In production, the most reliable agent use cases tend to be those with tight feedback loops and clear operational boundaries. Coding agents stand out because generated code can be executed and checked quickly, letting the system correct itself based on real errors. Web browsing agents are another common pattern: search, select pages, then perform question answering or navigation over retrieved content. Calendar and email management also appears as a practical fit because these tasks involve lots of incoming context and require actions like updating schedules or deleting events.
A key trade-off runs through the Q&A: chains are more predictable, while agents are harder to control but more flexible. The recommended workflow is to start with chains for simpler, linear tasks—especially when debugging and determinism matter—and move to agents when logic becomes branching, error recovery becomes essential, or multiple tools must be orchestrated.
Tool selection itself is handled through prompting and tool descriptions. Agents need explicit guidance on when to use tools, what each tool is for, and what tool outputs should look like. LangChain also emphasizes strategies to reduce failure modes: repeating tool-use instructions near the end of prompts to prevent “instruction forgetting,” retrieving only the most relevant subset of tools when tool libraries are large, and adding a dedicated “human clarification/input” tool to encourage asking questions instead of guessing. On the output side, agents often struggle to emit tool-invocation text in the right format, so LangChain uses structured outputs (like JSON), output parsers (including schema-driven parsing), and even a secondary LLM to repair malformed outputs.
Beyond agents, the discussion extends to practical architecture choices: for complex APIs, wrap each endpoint in its own chain so an agent can decide when to use the chain, while the chain handles the endpoint-specific translation from natural language to API parameters. For embeddings vs fine-tuning, the guidance favors retrieval-augmented generation for question answering because it’s easier to start, cheaper to update, and simpler to keep current as data changes. For large, fast-changing tabular data, the advice shifts toward SQL or pandas-based agents rather than chunking CSV text for retrieval.
Overall, the session frames LangChain as a developer-focused framework for building tool-using language model applications—paired with an emphasis on evaluation, cost tracking, and operational tooling to move from prototypes to production.
Cornell Notes
LangChain agents work by combining tool use with memory. A language model acts as a reasoning engine: it chooses tools (search, APIs, Python functions), reads tool observations (results or errors), and iterates toward a plan. Memory is crucial because models are stateless—LangChain discusses conversational memory, intermediate-step memory for multi-call workflows, and reflection-style state updates that can infer user preferences over time. For production, coding, web browsing, and calendar/email management are among the most practical agent patterns due to fast feedback and clear action loops. When tasks are simple and linear, chains are usually more predictable; agents become worth it when branching logic and error recovery are needed.
What makes an agent different from a basic LLM call in LangChain?
Why does memory matter for multi-step tool workflows?
Which production use cases were described as closest to working well with agents—and why?
When should developers choose chains over agents?
How does an agent decide which tool to use, and how is that made more reliable?
What architecture pattern helps with complex APIs?
Review Questions
- What three categories of memory were discussed for LangChain agents, and how does each one support tool-based reasoning?
- Why are chains often preferred for early production prototypes, and what specific failure modes push teams toward agents?
- Describe at least two techniques used to improve tool-use reliability when the model either forgets instructions or outputs malformed tool calls.
Key Points
- 1
LangChain agents combine tool use with memory: the model reasons, calls tools, ingests observations, and iterates toward a plan.
- 2
Conversational memory, intermediate-step memory, and reflection-style state updates are used to overcome stateless language model behavior.
- 3
Coding, web browsing, and calendar/email management are among the most practical agent patterns because they fit fast feedback and action loops.
- 4
Chains are more predictable for linear tasks; agents are better when branching logic, multi-tool orchestration, and error recovery become necessary.
- 5
Reliable tool use depends on strong prompt instructions plus accurate tool descriptions, and on structured output parsing (e.g., JSON + output parsers).
- 6
For complex APIs, wrap each endpoint in its own chain and let an agent choose which endpoint chain to invoke.
- 7
For question answering with changing data, retrieval-augmented generation via embeddings is generally easier to start and easier to keep current than fine-tuning.