Lecture 01: When to Use ML and Course Vision (FSDL 2022)
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
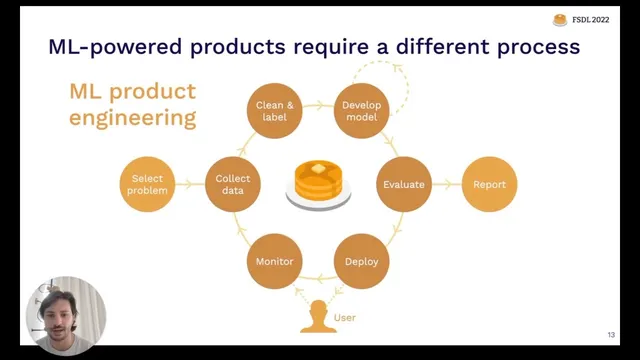
ML products need an outer loop—deploy, measure with real users, collect data, and iterate—because offline metrics don’t guarantee real-world performance.
Briefing
Machine learning is moving into the mainstream, but the real challenge isn’t getting models to work—it’s deciding when ML is worth the added complexity and then running an iterative loop that keeps performance aligned with real users. Full Stack Deep Learning frames the course around that gap: research-style model development (“flat earth ML”) often stops after a good offline metric, while production ML products require an outer loop that measures behavior in the wild, collects new data, and retrains or redesigns until the system stays useful.
The lecture starts by placing today’s ML boom in context. In 2018, standout systems like early language models were impressive but hard to apply; now there’s broader standardization and easier deployment. Model training is increasingly commoditized through tools and libraries (including Hugging Face-style workflows), deployment can be done with minimal code, and frameworks such as Keras and PyTorch Lightning reduce the “spaghetti code” burden. At the same time, MLOps has emerged as a discipline for deploying and maintaining models at scale, reflecting the field’s shift from prototypes to operational systems.
Avoiding an “AI winter,” the argument goes, depends less on research alone and more on translating progress into real products. That translation demands a different process than academic work: after deployment, teams must monitor real-world performance, gather feedback, and build a data flywheel so the model improves as the product learns. The course positions itself as end-to-end product building rather than a deep dive into theory or training math.
From there, the lecture pivots to the first practical question for any ML project: should ML be used at all? ML projects carry a higher failure rate than traditional software efforts, driven by common breakdowns—models that are technically feasible but too slow or expensive to ship, teams that can build models but can’t deploy them, organizational misalignment on what “success” means, and projects that solve the wrong problem or deliver insufficient business value. A key takeaway is that the value must outweigh not only development cost but also the technical debt and ongoing complexity ML introduces.
To decide readiness, the lecture recommends exhausting simpler options first. Teams should ask whether rules or basic statistics could achieve most of the benefit, whether the organization can collect and store the needed data, and whether the team and ethics are aligned. If ML is still the right choice, feasibility depends on impact and cost. High-impact opportunities often come from reducing prediction cost (making decisions feasible at scale), lowering user friction, or replacing brittle rule systems with learned behavior. Cost drivers include data availability (including labeling and stability), accuracy requirements (which can raise costs super-linearly as targets tighten), and intrinsic problem difficulty.
Finally, the lecture outlines how ML product work proceeds through a lifecycle: planning, data collection and labeling, training and debugging, and deployment and monitoring—each stage feeding back into the others when real-world constraints break assumptions. Using a running example of pose estimation for robotics, it emphasizes that offline success doesn’t guarantee downstream success; metrics, data, and requirements often need revision after testing in realistic environments. The overarching message: start with the right problem, ship early enough to learn, and build the operational loop that keeps ML systems effective over time.
Cornell Notes
Machine learning is increasingly easy to build, but ML products fail when teams treat model development like an endpoint. The lecture argues that success requires an outer loop: deploy the model, measure real-world performance, collect new data, and iterate so the system stays aligned with users. Before starting, teams should ask whether ML is necessary at all—ML adds complexity and technical debt, so the project’s value must outweigh that cost. Feasibility then depends on impact and cost, with data availability, accuracy requirements, and problem difficulty acting as major cost drivers. Finally, ML work follows a lifecycle (planning → data → training → deployment/monitoring) where each phase can force changes to the others based on what happens in production.
Why does the lecture treat “flat earth ML” as insufficient for real products?
What are the most common ways ML projects fail, even when the model looks promising?
How should teams decide whether ML is worth using at all?
What makes ML projects expensive as accuracy requirements rise?
What does “data flywheel” mean in the context of ML-powered products?
How does the ML project lifecycle work, and why does it loop?
Review Questions
- What outer-loop activities must happen after deployment to keep an ML product aligned with real user behavior?
- Which three cost drivers does the lecture emphasize for ML projects, and how does each affect feasibility?
- How do the three ML product archetypes (software 2.0, human-in-the-loop, autonomous systems) change the kinds of questions teams should ask before building?
Key Points
- 1
ML products need an outer loop—deploy, measure with real users, collect data, and iterate—because offline metrics don’t guarantee real-world performance.
- 2
Before using ML, teams should exhaust simpler options like rules or statistics and confirm they can collect and store the needed data.
- 3
ML projects often fail due to technical infeasibility, deployment/team mismatch, organizational misalignment on success criteria, or insufficient business value.
- 4
Feasibility should be judged using impact vs. cost, with data availability, accuracy requirements, and intrinsic problem difficulty as major cost drivers.
- 5
Tightening accuracy targets can raise costs super-linearly, often requiring more data and stronger monitoring to maintain performance.
- 6
ML work follows a lifecycle (planning → data → training → deployment/monitoring) where each phase can force changes to earlier assumptions.
- 7
Avoid tool fetishization: teams don’t need perfect infrastructure to start, but they do need the right problem and a practical path to production learning.