Lecture 02: Development Infrastructure & Tooling (FSDL 2022)
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Machine learning development is a loop: data preparation and labeling, model/weights selection, iterative debugging and experiments, deployment, monitoring, and then feeding new user data back into training.
Briefing
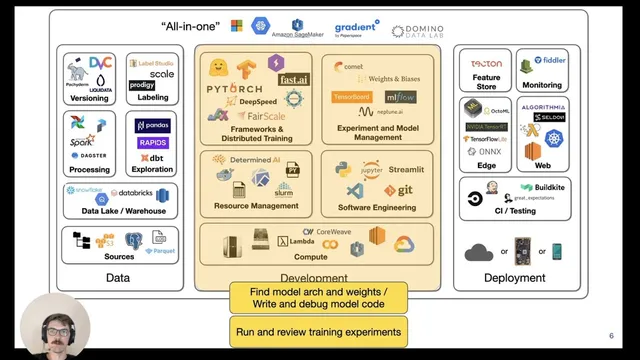
Machine learning development runs on a “data flywheel,” but getting from an idea to a reliable system at scale depends on disciplined software engineering—especially around tooling, reproducibility, and training infrastructure. The core workflow starts long before model code: teams must aggregate and clean data, label it, choose or train an architecture and pre-trained weights, iterate on model code through debugging and experiments, then deploy and monitor predictions. After deployment, user activity generates fresh data that must be fed back into the dataset, closing the loop.
That reality splits development into three practical layers: data and preparation (yellow), model development (the middle), and deployment (green). The lecture argues that most friction happens in the middle—where code, experiments, and environments must stay consistent while models evolve. Python is treated as the default language for ML because its ecosystem dominates scientific and data computing. From there, the tooling stack matters: editors like VS Code (recommended in the course) or PyCharm, notebook environments such as Jupyter/JupyterLab, and notebook workflows that enable fast feedback.
Notebooks are praised as a “first draft” environment because they provide immediate output and encourage rapid iteration. But they also create problems: limited refactoring support, weak versioning of cell outputs, out-of-order execution artifacts, and poor fit for unit testing. The lecture points to nbdev as a way to unify documentation, code, and tests inside notebooks, while still leveraging VS Code’s notebook support, remote editing via SSH, and debugging features like breakpoints.
For interactive sharing, Streamlit is highlighted as a way to turn Python scripts into lightweight web apps with widgets and efficient reruns. The lecture then shifts to environment management, emphasizing that deep learning setups are fragile: CUDA versions, Python versions, and library versions (e.g., PyTorch, NumPy) must align. A reproducible approach uses environment.yaml plus conda for Python/CUDA, then pip-tools to resolve compatible package versions and lock them so experiments can be recreated later. Makefiles can streamline common commands.
On the framework side, the lecture frames the choice as ecosystem and engineering fit. PyTorch is positioned as the full-stack default: it’s widely used in research and industry, supports CPU/GPU/TPU/mobile via an optimized execution graph, and has a strong distributed training ecosystem. PyTorch Lightning is recommended for structuring model code, optimizers, training loops, evaluation, and data loaders—making it easier to switch between single- and multi-device training with minimal code changes. Alternatives are acknowledged: TensorFlow (including Keras for layer composition), JAX for research and general vectorization/auto-differentiation, and meta-frameworks like Flax/Haiku.
Finally, scaling and compute management are treated as part of development infrastructure rather than an afterthought. Distributed training ranges from data parallelism (replicating the model across GPUs and averaging gradients) to sharded approaches for models that don’t fit on one GPU. Techniques like ZeRO-style optimizer/model sharding and Fully Sharded Data Parallel (FSDP) can cut memory usage dramatically, enabling much larger batch sizes and parameter counts. The lecture also surveys compute choices—NVIDIA GPUs, TPUs on GCP—and stresses that cost comparisons must consider time-to-train, not just hourly rates. For experiment and model management, it highlights tools such as TensorBoard, MLflow, Weights & Biases, and hyperparameter sweeps (e.g., Hyperband), plus all-in-one platforms that combine training, tracking, and deployment—while deferring deeper data and deployment topics to later weeks.
Cornell Notes
Machine learning development depends on more than model code: teams must build a reproducible pipeline that spans data preparation, experiment iteration, deployment, and monitoring—then feed new user-generated data back into training. Python is the default language, with notebooks enabling fast iteration but requiring extra discipline for versioning, testing, and execution order. Reproducible environments are achieved by pinning Python/CUDA versions and using pip-tools to resolve and lock compatible library versions. For training at scale, PyTorch Lightning structures training cleanly, while distributed strategies range from data parallelism to sharded methods like ZeRO/FSDP that reduce memory so larger models fit and train faster. Cost and performance comparisons should be based on total experiment time, not hourly GPU pricing.
Why does the “data flywheel” matter for development infrastructure, not just model accuracy?
What are the main strengths and weaknesses of notebook-first development?
How does the lecture recommend making ML environments reproducible?
When does distributed training move beyond simple data parallelism?
Why are cost comparisons based on total runtime rather than hourly GPU price?
Review Questions
- What specific notebook problems (execution order, versioning, testing) does the lecture identify, and what tooling approaches are suggested to mitigate them?
- Describe the progression from trivial parallelism to data parallelism to sharded model training. What problem triggers each step?
- How does pip-tools contribute to reproducibility compared with only pinning Python and CUDA versions?
Key Points
- 1
Machine learning development is a loop: data preparation and labeling, model/weights selection, iterative debugging and experiments, deployment, monitoring, and then feeding new user data back into training.
- 2
Python is treated as the practical default for ML because its library ecosystem dominates scientific and data computing.
- 3
Notebook workflows accelerate early iteration, but reproducibility requires addressing refactoring limits, cell output/versioning issues, and out-of-order execution artifacts.
- 4
Reproducible environments come from pinning Python/CUDA in environment.yaml (conda) and using pip-tools to resolve and lock compatible dependency versions.
- 5
PyTorch Lightning improves training maintainability by standardizing where model, optimizer, training, evaluation, and data loader code live while enabling multi-device runs with minimal changes.
- 6
Distributed training starts with data parallelism but requires sharded strategies (ZeRO/FSDP) when model parameters don’t fit on a single GPU.
- 7
Cloud cost should be evaluated by total experiment time and benchmarked throughput, not just hourly GPU pricing.