🚨🚨 Lets Talk o3 🚨🚨
Based on The PrimeTime's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
ARC Prize-style evaluations are used as a proxy for “AGI-like” generalization by testing whether models can infer and apply rules to new instances rather than rely on memorization.
Briefing
The central takeaway is that OpenAI’s o3 is a major step up in solving structured reasoning tasks—but the leap to “AGI” still looks more like impressive generalization on clean benchmarks than a clear, economically viable path to real-world autonomy. The discussion ties o3’s performance on ARC-style evaluations to a broader question: whether better puzzle-solving meaningfully predicts future software engineering capability, and at what cost.
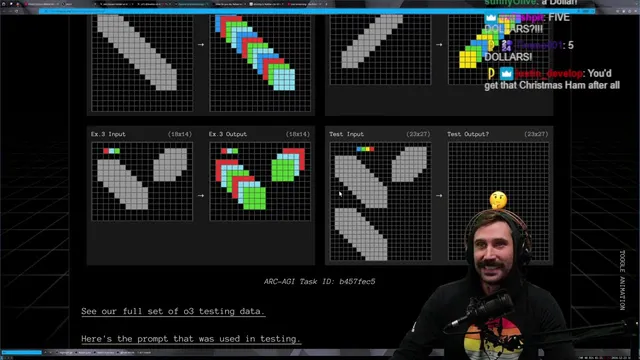
A key anchor is the ARC Prize framework, built to stress-test whether models can handle tasks that require learning new patterns rather than repeating memorized solutions. In that context, o3 is portrayed as dramatically outperforming earlier systems on an ARC AGI semi-private evaluation—described as “blowing it out of the water” compared with o1 and others. The argument for significance is not just higher accuracy, but the apparent ability to generalize across unseen puzzle instances: the speaker walks through examples where o3 can infer transformation rules from input/output grids and then apply them to new cases.
Still, the confidence comes with caveats. o3 is also said to fail on some “basic” tasks when the input space or rule framing doesn’t fully match what it needs to extrapolate. The transcript includes examples of color/laser-style puzzles and other structured transformations where the model either misses valid rule interpretations or struggles when the setup is too constrained or ambiguous relative to the intended rule. The takeaway is that o3’s generalization is real, but brittle—especially when the problem requires a more holistic interpretation than the model can reliably infer from the provided representation.
The discussion then pivots from benchmark performance to practical software engineering. The speaker argues that pattern recognition is the foundation of programming—data transformations, separation of concerns, and testability all reduce to recognizing and extending patterns. That makes o3’s puzzle performance feel relevant to coding. But the economics are the bottleneck: high-compute runs are described as too slow and too expensive for widespread use on large codebases. The speaker estimates that even if o3 can solve small tasks quickly, scaling to millions of lines of code would multiply context, search, and iteration costs, making “general-purpose developer” use untenable without massive cost reductions.
To illustrate the near-term reality, the transcript contrasts o3 with “Devon” (Devon), a tool positioned as more directly useful for coding workflows. Devon is praised for generating starting points and PRs that can be completed by a human, but criticized for integration gaps—finding core logic is easier than wiring it correctly across a real repository. Security risk is also raised as a major blocker for automated agents that can access repositories and run actions, with examples of API-key compromise concerns.
Finally, the transcript lands on a workforce outlook: jobs won’t disappear immediately because each wave of automation tends to shift work toward higher-level abstraction and new applications rather than eliminating the need for engineers outright. The speaker also rejects “don’t learn hard skills” takes, arguing that while AI can automate CRUD and rote algorithmic tasks, building larger systems and maintaining correctness, security, and integration still require human expertise. The future is framed as incremental: AI will keep improving, but practical, general-purpose usefulness likely depends on order-of-magnitude cost and capability gains—possibly alongside better tooling and safer agent design rather than AGI arriving fully formed.
Cornell Notes
o3 is presented as a significant upgrade in reasoning over ARC-style tasks, with performance described as far ahead of earlier models on structured evaluations. The speaker links that ability to programming as pattern recognition—arguing that coding often reduces to extending learned transformations. However, o3 is also described as failing on some tasks when the rule framing or input space doesn’t support reliable extrapolation, showing brittleness rather than human-level generality. The biggest obstacle to real-world impact is economics and scaling: high-compute usage is too slow and expensive for large codebases, and automated agents introduce security and integration risks. The result is a “useful but not AGI” stance: impressive benchmark gains, limited practical deployment without major cost and tooling improvements.
What is ARC Prize testing meant to measure, and why does it matter for “AGI” claims?
How does the transcript connect o3’s puzzle-solving to real programming work?
Why does the transcript claim o3 still struggles, even if it performs well on many ARC tasks?
What practical barrier prevents o3 from being widely useful as a coding agent right now?
How does Devon fit into the “agent” discussion, and what are its limitations?
What is the transcript’s stance on whether AI will eliminate programming jobs?
Review Questions
- What does the transcript suggest ARC-style evaluations reveal about a model’s generalization—and what do they not prove about AGI?
- According to the transcript, why do cost and context scaling matter more than raw speed when moving from puzzle tasks to large codebases?
- How does the speaker distinguish “hard skills” that remain valuable from tasks that AI can already automate well?
Key Points
- 1
ARC Prize-style evaluations are used as a proxy for “AGI-like” generalization by testing whether models can infer and apply rules to new instances rather than rely on memorization.
- 2
o3’s strong performance on structured ARC tasks is treated as meaningful for programming because coding often involves extending learned transformation patterns.
- 3
o3 is still described as brittle: some tasks are missed when the input framing or rule extrapolation doesn’t align with what the model can reliably infer.
- 4
Practical adoption is constrained less by raw capability and more by economics—high-compute time and cost scale poorly when moving from small puzzles to large repositories.
- 5
Automated coding agents like Devon can generate useful PRs and starting points, but they may struggle with integration details and introduce security risks.
- 6
The transcript argues that programming jobs won’t vanish immediately because automation shifts work toward higher-level abstraction and new software creation rather than removing engineering entirely.
- 7
The “don’t learn hard skills” message is rejected; the transcript frames hard skills as increasingly important for correctness, security, and system-level integration.