My PhD Thesis Outline - Planning for My Final Year as a Computer Science PhD Student
Based on Ciara Feely's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
The remaining 15 months of funding translate into a target to finish core research work in about six months, leaving roughly nine months for thesis writing.
Briefing
With just 15 months left of funding, a computer science PhD student in machine learning lays out a tightly sequenced plan to finish research and shift into thesis writing—aiming to “wrap up” core research within about six months so roughly nine months can go to drafting, revising, and finalizing the thesis.
The thesis centers on marathon training analytics using Strava data. The work focuses on turning complex, messy time-series training logs—each run session broken into 100-meter intervals with distance, time, pace, elevation, and heart-rate—into models that can (1) predict race performance, (2) quantify how training disruptions affect outcomes, and (3) recommend training plans to improve performance. The scale of the dataset grows dramatically across the PhD: early experiments used about 20,000 runners over 16 weeks, while later work expands to a couple million runners and tens of millions of sessions. That expansion forces new data engineering skills: extracting, cleaning, and re-running analyses at a much larger scale.
Early progress came quickly. In the first year, the student built features from training history to predict race times and produced two first-author conference publications, including work on training recommendations (what a “next week” might look like depending on whether a runner wants to improve or ease off). After the pandemic, the research focus shifted toward training disruptions—examining how breaks in training influence marathon performance—supported by multiple mini-projects and later journal submission.
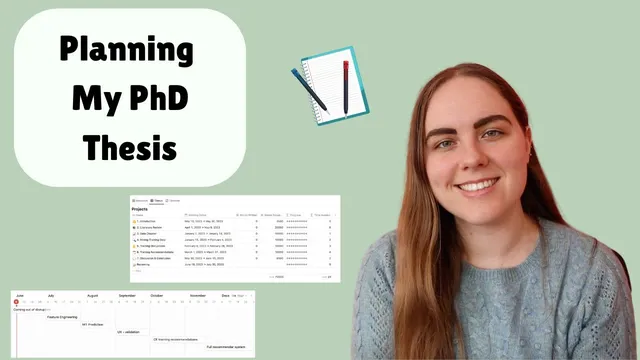
Structurally, the thesis is planned around the experiments rather than a purely linear “methods/results” flow. The outline includes an introduction chapter, a literature review, and a dedicated dataset chapter that documents how raw Strava data becomes usable modeling inputs, including the cuts and cleaning decisions required for a messy dataset. The core contribution is then split into three main chapters: (1) feature engineering and performance prediction, (2) training disruptions using more data-science-heavy analysis with some machine learning, and (3) training recommendations framed like a recommender system for marathon running.
A key practical challenge is validation for recommendations. Live user studies are unlikely, so validation is expected to rely on generating sample training plans and recruiting people to judge whether the plans are sensible and understandable—more “can humans follow this?” than “does it improve outcomes in the real world?”
For the remaining year, the student’s calendar is designed to front-load research during a less teaching-heavy summer. June priorities include finishing “camera-ready” material for an accepted conference paper and completing analysis for an additional training-disruptions piece that could become its own publication. The next phase targets feature engineering and representation learning for performance prediction, followed by a user-evaluation step to test explainability and usability of training plans. The final recommender-system work is scheduled for roughly October through December. Throughout, the student plans to write iteratively—capturing notes and drafts early—while avoiding premature full write-ups that might require rerunning models if the dataset changes again.
Cornell Notes
The PhD plan is built around a hard deadline: after passing a funding milestone, there are 15 months left to submit the thesis. The strategy is to finish most research in about six months, then devote roughly nine months to thesis writing. The research uses Strava time-series training data to (1) predict marathon race performance, (2) study how training disruptions affect outcomes, and (3) generate training recommendations. Work evolves from a smaller dataset (~20,000 runners) to a much larger one (millions of runners and tens of millions of sessions), requiring new data engineering and feature engineering. The thesis structure is experiment-driven, with a dedicated dataset chapter and a validation approach for recommendations based on human judgment rather than live trials.
Why does the thesis need a dedicated dataset chapter, and what does that chapter have to accomplish?
How does the research tackle marathon performance prediction using training history?
What changes when the dataset scales from tens of thousands of runners to millions?
What is the planned approach to validating training recommendations without a live user study?
How is the thesis organized to match the project’s experimental structure?
What is the student’s time-management logic for the final year?
Review Questions
- What specific validation method is planned for training recommendations, and why does it replace live user studies?
- How does the thesis’s chapter structure reflect the way the research was conducted (mini-projects and multiple experiments)?
- What are the main technical shifts required when moving from ~20,000 runners to a dataset with millions of runners and tens of millions of sessions?
Key Points
- 1
The remaining 15 months of funding translate into a target to finish core research work in about six months, leaving roughly nine months for thesis writing.
- 2
Marathon performance prediction is built from Strava time-series training data by engineering features from runners’ past sessions.
- 3
Dataset scale increases from ~20,000 runners to a couple million runners, requiring new data extraction, cleaning, and processing skills.
- 4
The thesis is organized around three contribution areas: feature engineering/performance prediction, training disruptions, and training recommendations.
- 5
Training recommendations are expected to be validated through human judgment of generated plans rather than live user trials.
- 6
A dedicated dataset chapter is treated as essential because it documents how messy raw Strava data becomes modeling-ready inputs.
- 7
The final-year schedule is designed to front-load research during a less teaching-heavy summer to reduce the risk of rework from dataset changes.