Parameter Efficient Fine Tuning
Based on West Coast Machine Learning's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Parameter-efficient fine-tuning freezes the pretrained Transformer backbone and trains only small task-specific parameters, reducing storage and distribution costs across many tasks.
Briefing
Parameter-efficient fine-tuning is presented as a practical way to adapt large Transformer and language models to new tasks without retraining the full weight set. Instead of updating every parameter with gradient descent, methods insert small, task-specific components—adapters, low-rank updates, or learned “prefix” key/value states—while freezing the original model. The payoff is lower storage and faster deployment of task specializations, since each new task can be shipped as a small parameter bundle rather than a full model checkpoint.
The baseline concept of fine-tuning is laid out first: start from a pre-trained model, change the output head if the label space differs, and then train with gradient descent while freezing some layers (often the entire backbone at first, then gradually unfreezing). Full fine-tuning yields a new complete parameter set, but it is expensive in both compute and—crucially for many real-world deployments—model distribution and storage.
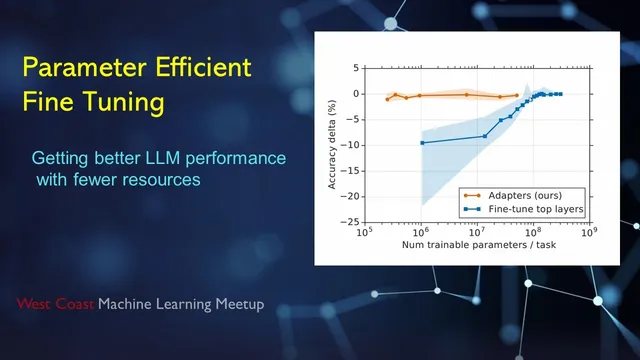
The talk then pivots to the 2019 adapter approach (Transformers adapters). Adapters are small bottleneck networks inserted into Transformer blocks (commonly around the feed-forward sublayer, sometimes also near attention). They include a skip connection so the adapter can behave like an identity mapping when needed, which helps preserve the original model’s behavior. During training, only the adapter parameters are updated; the rest of the Transformer remains frozen. Experiments on GLUE benchmark tasks are used to argue that adapter tuning can reach performance comparable to full fine-tuning while training far fewer parameters. The discussion emphasizes that the comparison is often framed in terms of parameter count (storage/transfer) more than raw compute, since the frozen backbone still runs during forward passes.
From there, the ecosystem expands. AdapterHub is described as a standardized way to publish and reuse these task-specific adapter modules, built by adding “hooks” into the Hugging Face Transformers library so adapters can be inserted into the residual stream. The talk also surveys several parameter-efficient alternatives:
LoRA (low-rank adaptation) decomposes weight updates into low-rank matrices, reducing the number of trainable parameters while still targeting key transformations (originally discussed for attention projections, but viewed as broadly applicable). Prefix tuning is framed as a different mechanism: rather than inserting a new module into the network, it learns extra “virtual” past key/value states that are prepended to the attention cache. These learned key/value vectors steer generation for a task while leaving the Transformer weights untouched. Prompt tuning and P-tuning are positioned as related variants that place learnable embeddings earlier in the pipeline (prompt/prefix learning), with P-tuning using an LSTM-based prompt encoder to generate task-specific virtual tokens.
The session closes with additional lightweight strategies such as IA3-style modulation, which adjusts intermediate activations using small learned scaling parameters instead of adding new sub-networks. Throughout, the central theme is modular specialization: large models can be adapted to many tasks by shipping small, composable parameter sets—improving practicality for multi-task systems where loading a full fine-tuned model per task would be too costly.
Cornell Notes
Parameter-efficient fine-tuning adapts large Transformer models to new tasks by training only a small set of task-specific parameters while freezing the original backbone. The classic baseline is full fine-tuning, where layers are unfrozen and updated with gradient descent, but that approach is costly to store and distribute for many tasks. Adapters (2019) insert small bottleneck networks with skip connections into Transformer blocks; training updates only those adapter weights and can match full fine-tuning performance on benchmarks like GLUE with far fewer trainable parameters. Prefix tuning and related prompt/p-tuning methods avoid inserting new modules by learning task-specific “virtual” past key/value states that steer attention during generation. The practical motivation is modularity: each new task can be packaged as a small parameter update (e.g., via AdapterHub) rather than a full model checkpoint.
How does full fine-tuning differ from parameter-efficient fine-tuning in what gets updated?
What is the core mechanism of the adapter approach (including why a skip connection matters)?
Why is AdapterHub important in practice?
How does prefix tuning steer a Transformer without changing its weights?
What distinguishes prompt tuning, prefix tuning, and P-tuning?
What is IA3-style modulation in this landscape?
Review Questions
- When adapting a pretrained model to a new label space, which parts of the architecture typically change under full fine-tuning, and which parts stay frozen under adapter-based tuning?
- Explain how prefix tuning uses learned past key/value states to condition generation while keeping Transformer weights unchanged.
- Compare adapters and LoRA: where do the trainable parameters live, and what kind of transformation do they approximate or replace?
Key Points
- 1
Parameter-efficient fine-tuning freezes the pretrained Transformer backbone and trains only small task-specific parameters, reducing storage and distribution costs across many tasks.
- 2
Adapters insert bottleneck networks with skip connections into Transformer blocks; only adapter weights are updated, and performance can approach full fine-tuning on benchmarks like GLUE.
- 3
AdapterHub standardizes how adapters are published and reused by integrating with Hugging Face Transformers via hooks that insert adapter modules into the residual stream.
- 4
LoRA reduces trainable parameter count by expressing weight updates as low-rank matrix decompositions, targeting key linear transformations (often attention projections).
- 5
Prefix tuning conditions a frozen model by learning task-specific “virtual” past key/value states that are prepended to the attention cache.
- 6
Prompt tuning, P-tuning, and related prompt-learning variants differ mainly in where the learnable task parameters are injected (embedding side vs attention key/value side) and how they are generated (e.g., LSTM prompt encoder).
- 7
Lightweight modulation methods like IA3 adjust intermediate activations with small learned scaling parameters rather than adding new networks.