Understanding ReACT with LangChain
Based on Sam Witteveen's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
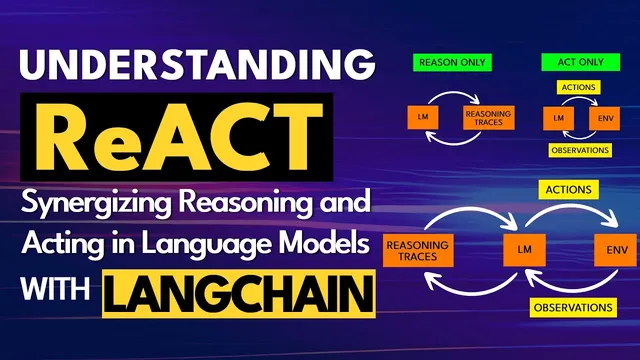
ReACT improves LLM reliability by iterating through thought traces, tool actions, and tool-returned observations until a final answer is justified by evidence.
Briefing
ReACT (Reasoning and Action) is a prompting-and-agent pattern designed to make large language models do multi-step problem solving by alternating between internal “thought” traces, tool-using “actions,” and tool-returned “observations.” The core advantage is that answers improve when the model doesn’t just justify an initial guess; instead, it gathers evidence through actions and then revises its reasoning step by step until it can finish. That matters because getting LLMs to reliably follow instructions—rather than confidently hallucinating—remains one of the hardest practical challenges.
The approach builds on two earlier ideas. First is chain-of-thought prompting, where asking for reasoning up front can raise performance: the model’s reasoning becomes a primer for the final answer, rather than a post-hoc justification. Without that structure, the model tends to produce an answer immediately and then “double down” by rationalizing it, which can amplify errors. Second is action-in-environment prompting, associated with methods like SayCan, where the model uses actions and then consumes the resulting observations to guide subsequent steps.
ReACT combines both. It starts with reasoning traces, then issues an action—typically a tool call such as Wikipedia search or lookup—then ingests the observation returned by that tool. Crucially, the observation feeds back into the model to generate the next thought and next action. This repeats over multiple cycles, producing a reasoning process that is both traceable and grounded in external information. In the HotpotQA-style example described, a question requiring multiple facts (searching for a topic, finding an author, then checking where the author worked) is solved by iteratively searching, reading observations, and updating the next step until the final answer can be produced.
A key implementation detail is that ReACT often uses many more tokens and multiple model calls: the prompt includes several in-context examples that teach the “thought → action → observation → next thought” rhythm. The transcript also highlights a limitation: many open-source models struggle with this pattern because they may lack the token budget to fit the long priming examples and may not be trained to produce reliable reasoning traces in the same way. Larger models (the transcript mentions text-davinci-003 and notes GPT-4 as a stronger reasoning choice) tend to perform better.
The LangChain walkthrough shows how the pattern is operationalized. An agent is set up with a toolset (notably a Wikipedia tool with search and lookup), an LLM generates structured outputs containing “thought” and “action,” and an output parser extracts the intended tool call. The tool runs, returns an observation, and the agent re-prompts the model with the updated scratchpad (accumulated thoughts, actions, and observations). The example of asking “how old is the president of the United States?” demonstrates how the model can search for the president, then use the observation to compute an age—while also acknowledging that the model may assume a fixed “current year” unless the question changes.
Finally, the transcript warns against a common misuse: copying the ReACT prompt examples verbatim. Better results come from customizing the in-context examples—thoughts, actions, observations, and tool usage—to match the domain and tasks at hand (e.g., finance questions should use finance-relevant tool interactions). ReACT’s power, in short, comes from grounding reasoning in tool-driven observations and iterating until the model can stop with a well-supported final answer.
Cornell Notes
ReACT (Reasoning and Action) improves LLM task performance by forcing an iterative loop: the model produces a “thought,” performs an “action” via tools (e.g., Wikipedia search/lookup), receives an “observation,” and then uses that observation to generate the next thought. Compared with chain-of-thought alone, this reduces post-hoc justification and helps the model correct itself using external evidence. Compared with action-only approaches, it keeps reasoning traces explicit and updated after each tool result. In LangChain, an output parser extracts the tool call from the model’s structured response, runs the tool, and appends the observation to an agent scratchpad for the next reasoning step. Customizing the in-context examples and tool set to the target domain is emphasized for best results.
Why does chain-of-thought prompting often outperform “answer-first” prompting?
How does ReACT differ from chain-of-thought and action-only methods?
What goes wrong when ReACT prompting is used without actually connecting tools?
How does LangChain’s ReACT loop work under the hood?
Why does ReACT often require many tokens, and why can open-source models struggle?
What customization step improves ReACT performance for real projects?
Review Questions
- In what way can “answer-first” behavior increase hallucinations, and how does chain-of-thought change that dynamic?
- Describe the sequence of thought, action, observation, and scratchpad update in LangChain’s ReACT implementation.
- Why might a ReACT prompt work well with a large model but fail with many open-source models?
Key Points
- 1
ReACT improves LLM reliability by iterating through thought traces, tool actions, and tool-returned observations until a final answer is justified by evidence.
- 2
Chain-of-thought can boost performance by priming reasoning before the answer, but it can still devolve into post-hoc justification without external grounding.
- 3
Action-only approaches gain grounding from environment feedback, but ReACT keeps reasoning explicit and updated after each observation.
- 4
In LangChain, an output parser extracts tool calls from the model’s structured output, runs the tool, and appends observations to an agent scratchpad for the next reasoning step.
- 5
ReACT often uses more tokens because it relies on multiple in-context examples and multiple model calls across steps.
- 6
ReACT without real tool wiring leads to hallucinated observations, since the model will invent tool results it never actually received.
- 7
Customizing ReACT’s in-context examples and tool set to the target domain (not copying the paper’s examples blindly) is key to better results.